今天我们来检验一个用SQL SERVER 2005或者以后版本中的CTE和ROW_NUMBER() 功能来删除重复数据复本的代码片段。
首先,我们需要创建一个用于测试的表,并在该表里插入几条数据(包括重复的数据),代码如下:
 关于批量删除的最有趣的部分来了,我们将用SQL SERVER 的CTE,它将重新生成一个相同的但附加了一行编号的表。在此方案中,我们有Col1,Col2以及包含这个两列重复数的列,对于不同的查询,这个重复数的列可能有不同的值。另一点需要注意的是,一旦CTE被创建,DELETE语句就可以被运行了。这里我们设置一个条件——当我们读取到的记录大于一条(即有重复数据),我们删除除了第一条的所有其他(这里可能有点绕,简单的话就是保留一条重复的记录)。删除代码:
温馨提示:删除操作危险,请在操作前一定再三确认好了,我自己是吃了几次亏的啊。。。
关于批量删除的最有趣的部分来了,我们将用SQL SERVER 的CTE,它将重新生成一个相同的但附加了一行编号的表。在此方案中,我们有Col1,Col2以及包含这个两列重复数的列,对于不同的查询,这个重复数的列可能有不同的值。另一点需要注意的是,一旦CTE被创建,DELETE语句就可以被运行了。这里我们设置一个条件——当我们读取到的记录大于一条(即有重复数据),我们删除除了第一条的所有其他(这里可能有点绕,简单的话就是保留一条重复的记录)。删除代码:
温馨提示:删除操作危险,请在操作前一定再三确认好了,我自己是吃了几次亏的啊。。。
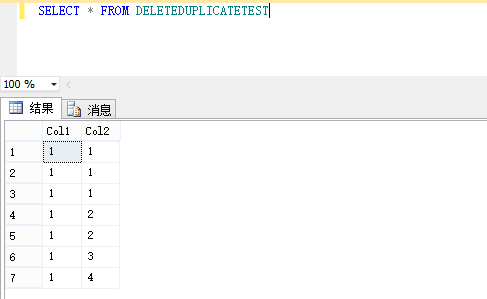
/* Create Table with 7 records- 3 are duplicate records*/ CREATE TABLE DeleteDuplicateTest(Col1 INT, Col2 INT) INSERT INTO DeleteDuplicateTest SELECT 1, 1 UNION ALL SELECT 1, 1 --duplicate UNION ALL SELECT 1, 1 --duplicate UNION ALL SELECT 1, 2 UNION ALL SELECT 1, 2 --duplicate UNION ALL SELECT 1, 3 UNION ALL SELECT 1, 4 GO以上的7条数据,其中包括3条重复的数据复本,当执行删除重复操作后,我们将得到如下图所示的4条惟一的记录
 关于批量删除的最有趣的部分来了,我们将用SQL SERVER 的CTE,它将重新生成一个相同的但附加了一行编号的表。在此方案中,我们有Col1,Col2以及包含这个两列重复数的列,对于不同的查询,这个重复数的列可能有不同的值。另一点需要注意的是,一旦CTE被创建,DELETE语句就可以被运行了。这里我们设置一个条件——当我们读取到的记录大于一条(即有重复数据),我们删除除了第一条的所有其他(这里可能有点绕,简单的话就是保留一条重复的记录)。删除代码:
关于批量删除的最有趣的部分来了,我们将用SQL SERVER 的CTE,它将重新生成一个相同的但附加了一行编号的表。在此方案中,我们有Col1,Col2以及包含这个两列重复数的列,对于不同的查询,这个重复数的列可能有不同的值。另一点需要注意的是,一旦CTE被创建,DELETE语句就可以被运行了。这里我们设置一个条件——当我们读取到的记录大于一条(即有重复数据),我们删除除了第一条的所有其他(这里可能有点绕,简单的话就是保留一条重复的记录)。删除代码:
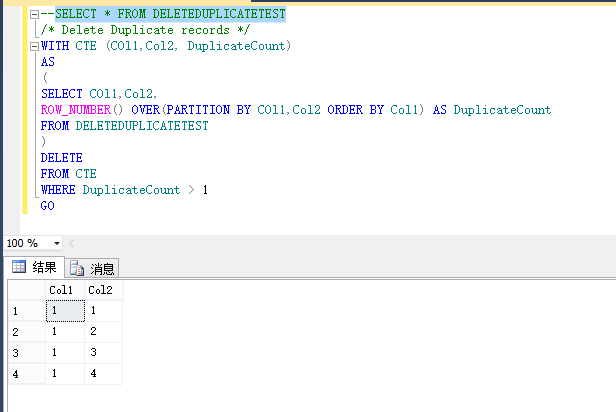
/* Delete Duplicate records */ WITH CTE (COl1,Col2, DuplicateCount) AS ( SELECT COl1,Col2, ROW_NUMBER() OVER(PARTITION BY COl1,Col2 ORDER BY Col1) AS DuplicateCount FROM DELETEDUPLICATETEST ) DELETE FROM CTE WHERE DuplicateCount > 1 GO执行以上语句,再次查询我们的测试表,只有4条结果了,结果如下图:
 温馨提示:删除操作危险,请在操作前一定再三确认好了,我自己是吃了几次亏的啊。。。
温馨提示:删除操作危险,请在操作前一定再三确认好了,我自己是吃了几次亏的啊。。。
版权声明:本作品系原创,版权归码友网所有,如未经许可,禁止任何形式转载,违者必究。

发表评论
登录用户才能发表评论, 请 登 录 或者 注册