网上看到一本关于微服务反模式的电子书,看后感觉内容非常棒,于是我决定分阶段翻译成中文书,翻译的目的也是想帮助想深入了解微服务的朋友,由于英文水平有限,如有翻译不对之处希望多留言指正。
书籍英文目录如下

微服务会创建大量小的、分布式的、单一用途的服务,每个服务拥有自己的数据。这种服务和数据耦合支持一个有界的上下文和一个无共享数据的架构,其中,每个服务及其对应的数据是独立一块,完全独立于所有其他服务。服务只暴露了一个明确的接口(服务契约)。有界的上下文可以允许开发者以最小的依赖快速轻松地开发,测试和部署。
采用数据驱动迁移反模式主要发生在当你从一个单体应用向微服务架构做迁移的时候。我们之所以称之为反模式主要原因是,刚开始我们觉得创建微服务是一个不错的主意,服务和相应的数据都独立成微服务,但这可能会将你带向一个错误的道路上,导致高风险、过剩成本和额外的迁移工作。
单体应用迁移到微服务架构有两个主要目标:
- 第一个目标是单体应用程序的功能分割成小的,单一用途的服务。
- 第二个目标是单体应用的数据迁移到每个服务自己独占的小数据库(或独立的服务)。
下图展示了一个典型的迁移,看起来像服务代码和相应的数据同时进行迁移。
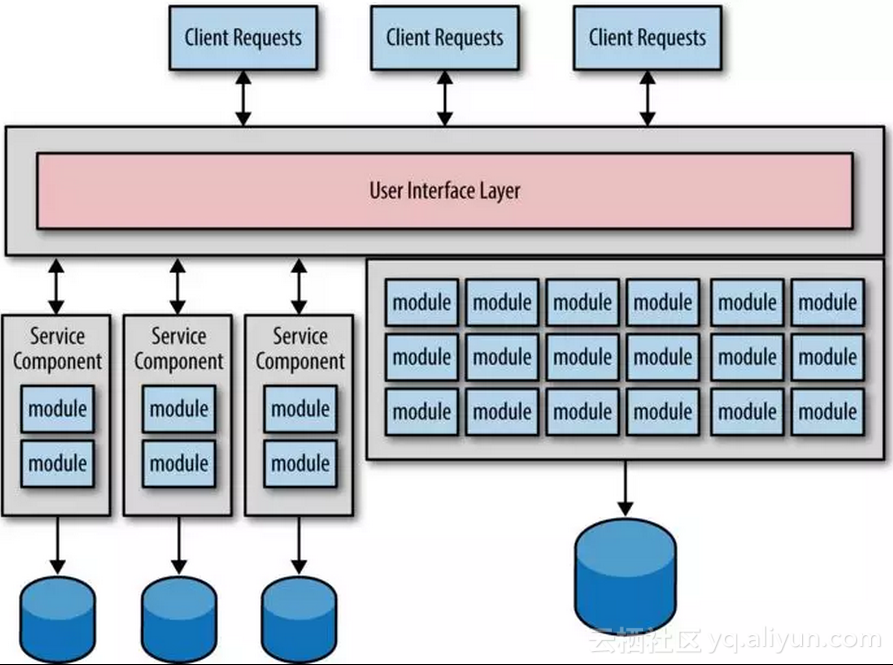
图1-1
上图中有三个服务是从单体应用中划分而来,并且还划分独立的三个数据库,这是一个自然演变的过程,因为在每个服务和数据库之间都使用了最为关键的限界上下文,然而我们遇到的问题也正是基于这一过程将带领我们进入数据迁移的反模式。
1.1 太多的数据迁移
这种迁移路径的主要问题是,我们很难在一次就能够划分清楚每个服务的粒度,从一个更粗粒度的服务开始着手,一步步的进行细化工作,并且要多了解相关业务知识,不断的对服务的粒度进行调整,我们来看图1-1发现最左边的服务粒度太粗了,需要再拆分成二个小的服务,或者你发现左边的二个服务粒度划分的又太细了,需要进行合并。而数据迁移要比源代码迁移更复杂,更容易出错,我们最好只为数据进行一次迁移工作,因为数据迁移是一个高风险的工作。
我们的微服务划分也就是应用代码的迁移和数据的迁移。如图1-2所示。
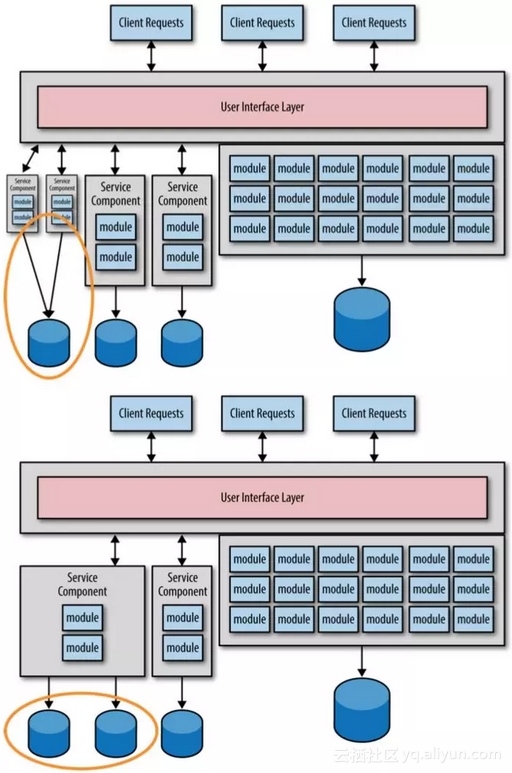
图1-2
1.2 功能分割优先,数据迁移最后
此模式主要采用的是一种避免的手段,以迁移服务的功能为第一,同时也需要注意服务和数据之间的限界上下文。我们可以通过合并与拆分的手段对服务进行调整直到满意为止,这时候就可以迁移数据了。
如图1-3所示,左边所有三个服务都已经进行了迁移和拆分,但是所有服务仍然使用的是同一个数据库,如果这是一个临时中间方案还可以作为一个选择,这时候我们就需要更多的了解服务如何使用,以及接受什么类型的请求数据等。
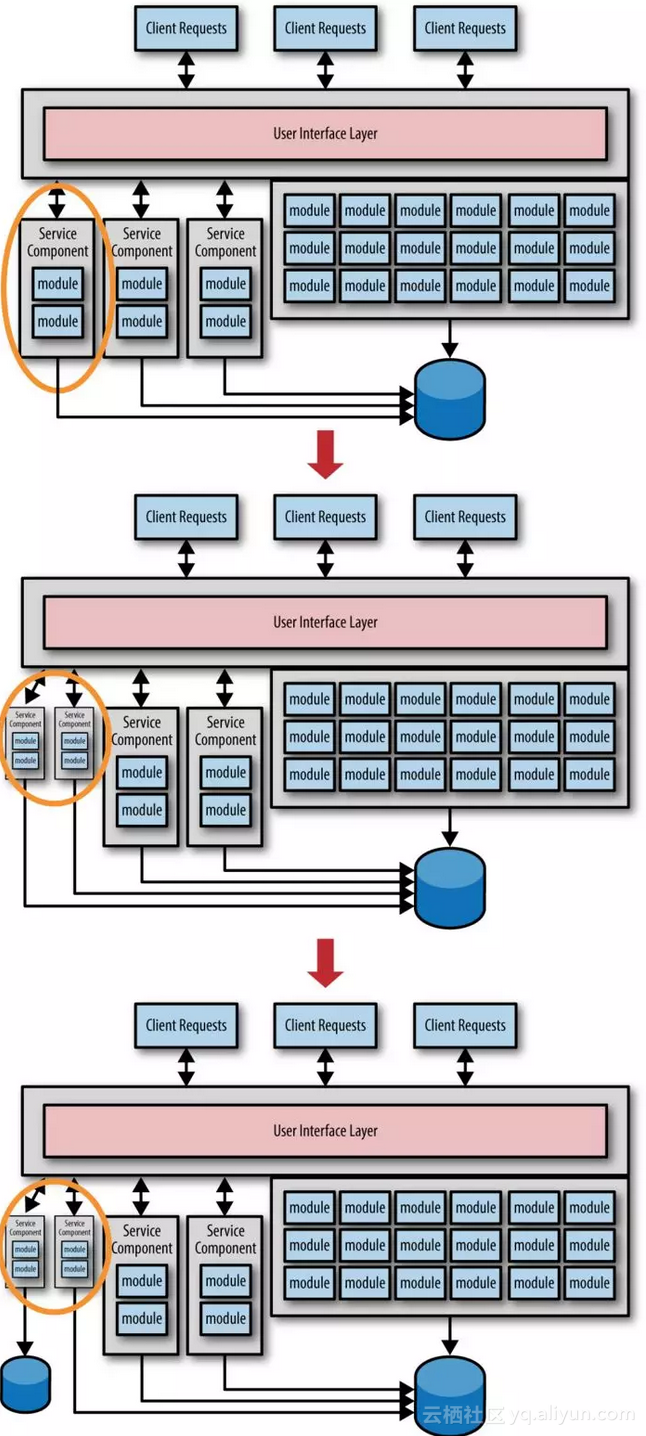
图1-3
在图1-3中,我们要注意最左边的服务是如何发现粒度太粗而拆分成二个服务的。服务粒度最终确定完成之后,下一步就开始迁移数据了,采用这种方式可以避免重复的数据迁移。
二、超时反模式
微服务是一种分布式的架构,它所有的组件(也就是服务)会被部署为单独的应用程序,并通过某种远程访问协议进行通讯。分布式应用的挑战之一就是如何管理远程服务的可用性和它们的响应。虽然服务可用性和服务响应都涉及到服务的通信,但它们是两个完全不同的东西。服务可用性是服务消费者连接服务并能够发送请求的能力,服务响应则关注服务的响应时间。
图2-1
如图2-1的所示,如果此时服务消费者无法连接到服务提供者的时候,通过会在毫秒级的时间里得到通知和反馈,这时候服务消费者可以选择是直接返回错误信息还是进行重试,但是如果服务提供者接收了请求却不进行响应该怎么办,在这种情况下服务消费者可以选择无限期等待或者设置超时时间,使用超时时间看起来是个好办法,但是它会导致超时反模式。
2.1 使用超时
你可能感觉非常困惑,难道设置一个超时时间不是一件好事吗?在大部分的情况下超时时间的错误设置都会带来问题。比如当你上网购物的时候,你提交了订单,服务一直在处理没有返回,你在超时的时候再提交订单,显然服务器需要更复杂的逻辑来处理重复提交订单的问题。
那么超时时间设置多少合适呢?
- 第一种是基于数据库的超时来计算服务的超时时间。
- 第二种是计算负载下最长的处理时间,把它乘以2作为超时时间。
在图2-2中,通常的情况下平均响应时间是2秒,在高并发的情况下最长时间是5秒,因为可以使用加倍技术服务的超时时间设置为10秒。
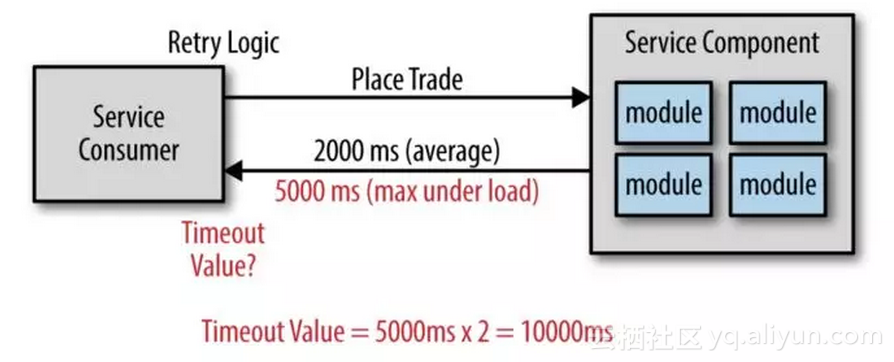
图2-2
图2-2的解决方案似乎看起来很完美,它使每一个服务消费者必须等待10秒,其实只是为了判断服务没有响应。在大多数情况下,用户在等待提交按钮或放弃和关闭屏幕之前不会等待超过2到3秒。那就必须要有更好的办法来解决。
2.2 使用断路器模式
与上面超时的方法相比,使用断路器的方式更为稳妥,这种设计模式就像家里的电器的保险丝一样,当负载过大,或者电路发生故障或异常时,电流会不断升高,为防止升高的电流有可能损坏电路中的某些重要器件或贵重器件,烧毁电路甚至造成火灾。保险丝会在电流异常升高到一定的高度和热度的时候,自身熔断切断电流,从而起到保护电路安全运行的作用。
图2-3说明了断路器模式是如何工作的,当服务保持响应时,断路器将关闭,允许通过请求。如果远程服务突然变得不能响应,断路器就会打开,从而阻止请求通过,直到服务再次响应。当然这并不像你家中的保险丝,断路器本身可以持续监测服务。
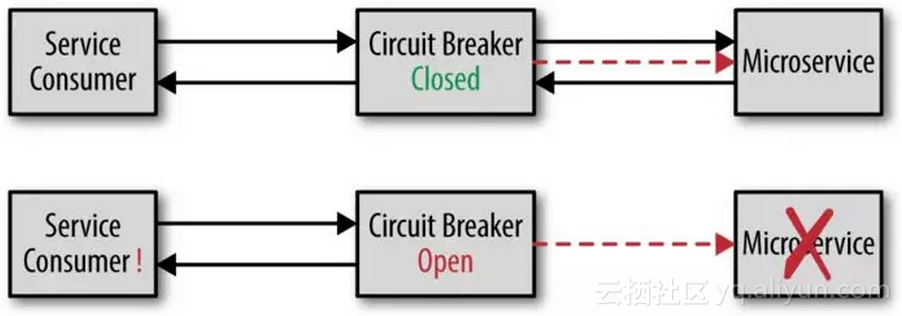
图2-3
断路器模式相比设置超时的优点是,使用者可以立即知道服务已变得不响应,而不必等待超时,使用者将在毫秒内服务不响应,而不是等待10秒获得相同的信息。
另外断路器可以通过几种方式进行监控,最简单的方法是对远程服务进行简单的心跳检查,这种方式只是告诉断路器服务是活的,但是要想获取服务存活的详细信息,就需要定期(比如10秒)获取一次服务的详细信息,还有一种方式是实时用户监控,这种方式可以动态调整,一旦达到阈值,断路器可以进入半开放状态,可以设置一定数量的请求是通过(说1的10)。
三、共享反模式
微服务是一种无共享的架构,我更倾向于叫它为“尽量不共享”模式(share-as-little-as-possible), 因为总有一些代码会在微服务之间共享。比如不提供一个身份验证的微服务,而是将身份验证的代码打包成一个jar文件:security.jar,其它服务都能使用。如果安全检查是服务级别的功能,每个服务接收到请求都会检查安全性,这种方式可以很好的提高性能。
然后如果太过频繁的使用最终会出现依赖噩梦,如图3-1所示,其中每个服务都依赖于多个自定义共享库。
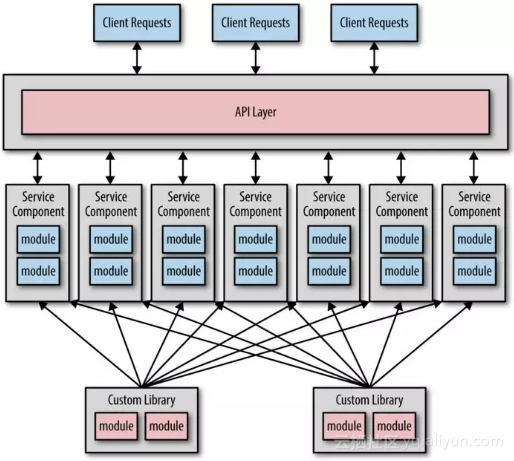
图3-1
这种共享级别不仅破坏了每个服务的限界上下文,而且还引入了几个问题,包括整体可靠性、更改控制、可测试性和部署能力。
3.1 过多依赖
在面向对象的软件开发过程中,经常会遇到共享的问题,特别是从单一分层结构迁移到微服务结构时,图3-2展示抽象类和共享,它们最终在多数单块分层体系结构中共享。
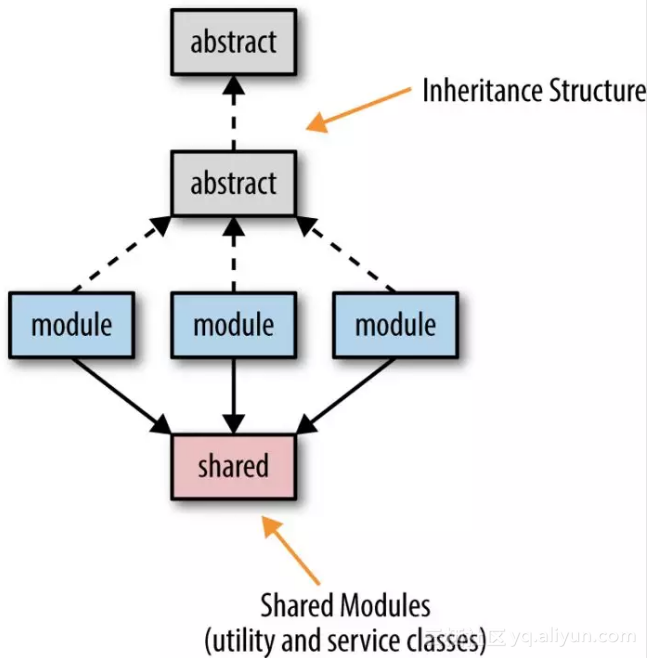
图3-2
创建抽象类和接口是面向对象编程的最重要做法,那我们如何来处理数百个服务共享的代码?
微服务架构的主要目标就是共享要尽可能的少,这有助于维护服务的限界上下文,使我们能够快速的测试和布署。服务之间依赖越强,服务隔离也就越困难,因此也就越难单独进行测试和布署。
3.2 共享代码的技术
要避免这个反模式的最好办法就是代码不共享,但是实际工作中总会有一些代码需要进行共享,那这些共享代码应该放到哪里呢?
图3-3给了四个最基本的技术:
注:本文内容来自互联网,旨在为开发者提供分享、交流的平台。如有涉及文章版权等事宜,请你联系站长进行处理。