
本文简单的介绍下kafka,主要包含以下部分:
- 什么是Kafka
- Kafka的基本概念
- Kafka分布式架构
- 配置单机版Kafka
- 实验一:kafka-python实现生产者消费者
- 实验二:消费组实现容错性机制
- 实验三:offset管理
什么是Kafka
Kafka是一个分布式流处理系统,流处理系统使它可以像消息队列一样publish或者subscribe消息,分布式提供了容错性,并发处理消息的机制。
Kafka的基本概念
kafka运行在集群上,集群包含一个或多个服务器。kafka把消息存在topic中,每一条消息包含键值(key),值(value)和时间戳(timestamp)。
kafka有以下一些基本概念:
Producer - 消息生产者,就是向kafka broker发消息的客户端。
Consumer - 消息消费者,是消息的使用方,负责消费Kafka服务器上的消息。
Topic - 主题,由用户定义并配置在Kafka服务器,用于建立Producer和Consumer之间的订阅关系。生产者发送消息到指定的Topic下,消息者从这个Topic下消费消息。
Partition - 消息分区,一个topic可以分为多个 partition,每个
partition是一个有序的队列。partition中的每条消息都会被分配一个有序的
id(offset)。
Broker - 一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
Consumer Group - 消费者分组,用于归组同类消费者。每个consumer属于一个特定的consumer group,多个消费者可以共同消息一个Topic下的消息,每个消费者消费其中的部分消息,这些消费者就组成了一个分组,拥有同一个分组名称,通常也被称为消费者集群。
Offset - 消息在partition中的偏移量。每一条消息在partition都有唯一的偏移量,消息者可以指定偏移量来指定要消费的消息。
Kafka分布式架构
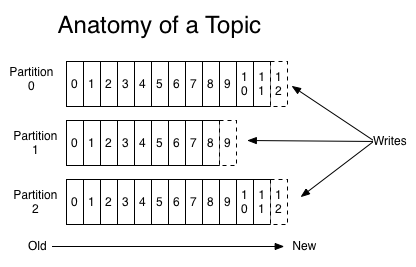
如上图所示,kafka将topic中的消息存在不同的partition中。如果存在键值(key),消息按照键值(key)做分类存在不同的partiition中,如果不存在键值(key),消息按照轮询(Round Robin)机制存在不同的partition中。默认情况下,键值(key)决定了一条消息会被存在哪个partition中。
partition中的消息序列是有序的消息序列。kafka在partition使用偏移量(offset)来指定消息的位置。一个topic的一个partition只能被一个consumer group中的一个consumer消费,多个consumer消费同一个partition中的数据是不允许的,但是一个consumer可以消费多个partition中的数据。
kafka将partition的数据复制到不同的broker,提供了partition数据的备份。每一个partition都有一个broker作为leader,若干个broker作为follower。所有的数据读写都通过leader所在的服务器进行,并且leader在不同broker之间复制数据。
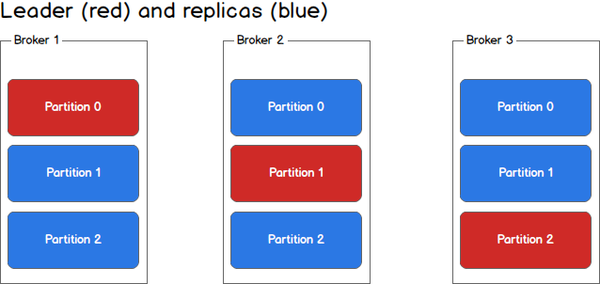
上图中,对于Partition 0,broker 1是它的leader,broker 2和broker 3是follower。对于Partition 1,broker 2是它的leader,broker 1和broker 3是follower。
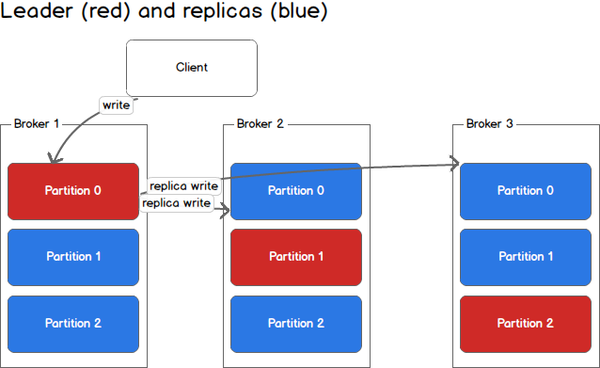
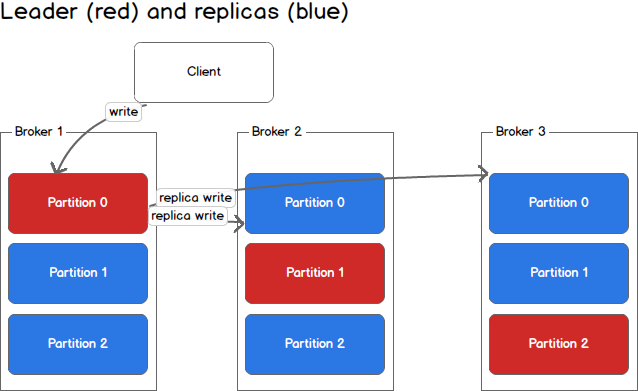
在上图中,当有Client(也就是Producer)要写入数据到Partition 0时,会写入到leader Broker 1,Broker 1再将数据复制到follower Broker 2和Broker 3。
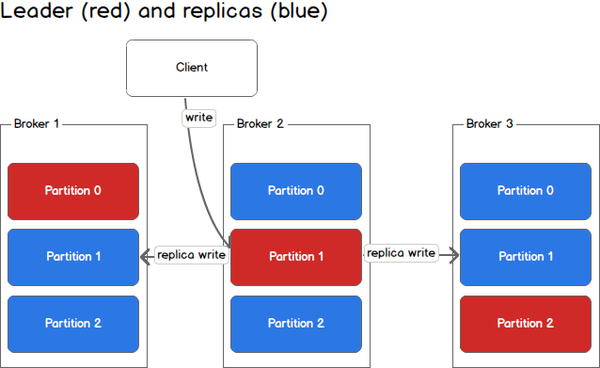
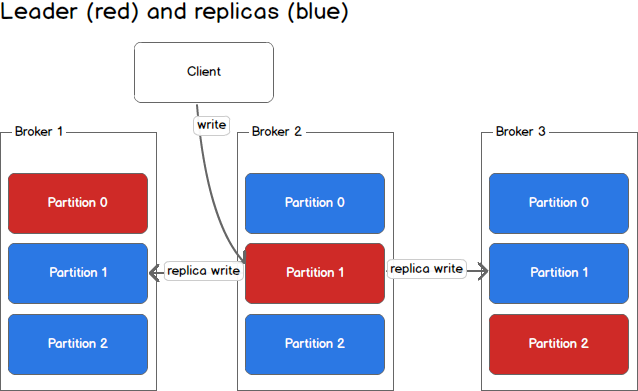
在上图中,Client向Partition 1中写入数据时,会写入到Broker 2,因为Broker 2是Partition 1的Leader,然后Broker 2再将数据复制到follower Broker 1和Broker 3中。
上图中的topic一共有3个partition,对每个partition的读写都由不同的broker处理,因此总的吞吐量得到了提升。
配置单机版Kafka
这里我们使用kafka 0.10.0.0版本。
第一步:下载并解压包
$ wget https://archive.apache.org/dist/kafka/0.10.0.0/kafka_2.11-0.10.0.0.tgz$ tar -xzf kafka_2.11-0.10.0.0.tgz$ cd kafka_2.11-0.10.0.0第二步:启动Kafka
kafka需要用到zookeeper,所以需要先启动zookeeper。我们这里使用下载包里自带的单机版zookeeper。
$ bin/zookeeper-server-start.sh config/zookeeper.properties[2013-04-22 15:01:37,495] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)...然后启动kafka
$ bin/kafka-server-start.sh config/server.properties[2013-04-22 15:01:47,028] INFO Verifying properties (kafka.utils.VerifiableProperties)[2013-04-22 15:01:47,051] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties)...第三步:创建topic
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test查看创建的topic
$ bin/kafka-topics.sh --list --zookeeper localhost:2181test第四步:向topic中发送消息
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testThis is a messageThis is another message第五步:从topicc中消费消息
$ bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginningThis is a messageThis is another message实验一:kafka-python实现生产者消费者
kafka-python是一个python的Kafka客户端,可以用来向kafka的topic发送消息、消费消息。
这个实验会实现一个producer和一个consumer,producer向kafka发送消息,consumer从topic中消费消息。结构如下图


producer代码
# producer.pyimport timefrom kafka import KafkaProducerproducer = KafkaProducer(bootstrap_servers="localhost:9092")i = 0while True: ts = int(time.time() * 1000) producer.send(topic="test", value=str(i), key=str(i), timestamp_ms=ts) producer.flush() print i i += 1 time.sleep(1)consumer代码
# consumer.pyfrom kafka import KafkaConsumerconsumer = KafkaConsumer("test", bootstrap_servers=["localhost:9092"])for message in consumer: print message接下来创建test topic
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testCreated topic "test".打开两个窗口中,我们在window1中运行producer,如下
# window1$ python producer.py0
注:本文内容来自互联网,旨在为开发者提供分享、交流的平台。如有涉及文章版权等事宜,请你联系站长进行处理。