本次爬虫所要爬取的数据为京东建材数据,在爬取京东的过程中,发现京东并没有做反爬虫动作,所以爬取的过程还是比较顺利的。
为什么要用WebMagic:
- WebMagic作为一款轻量级的Java爬虫框架,可以极大的减少爬虫的开发时间
为什么要使用MQ(本项目用的RabbitMq,其他的MQ也可以):
- 解耦各个模块,实现各个爬虫之间相互独立
- 项目健壮性,不管是主动还是被动原因(断电等状况)停下了项目,只需要重新读取MQ中的数据就能继续工作
- 拆分了业务逻辑,使每个模块更加简单。代码易于编写
为什么要用ES:
- 方便后期搜索
- 业务需求
项目大体架构图:
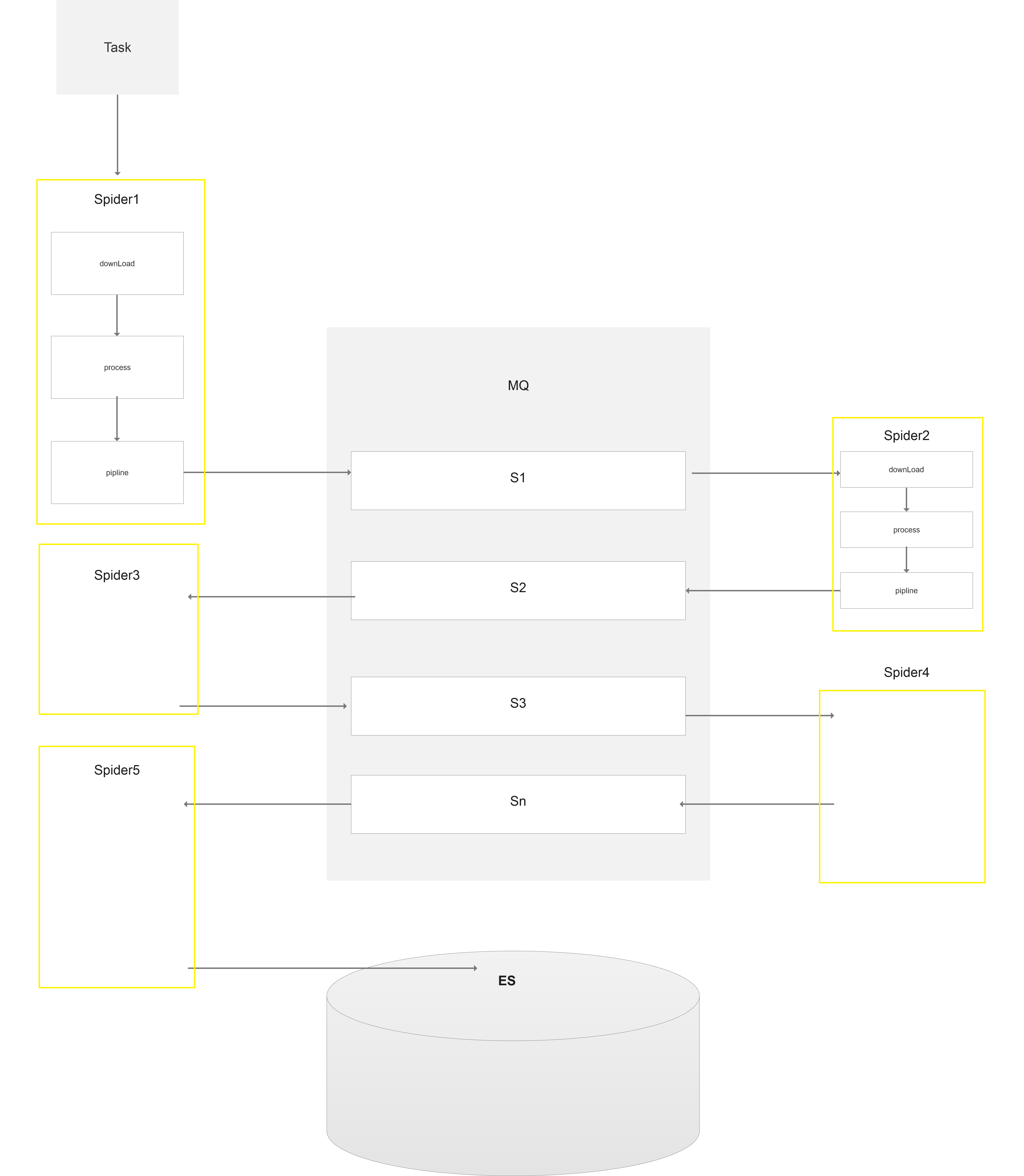
此处有多个spider,前面几层的spider分别处理不同模块的数据,将处理好的数据放入mq,供下一级的spider来调用。
本次爬取的最终页面是商品的详情页,所以最后一级的spider将详情数据爬取完之后存储到ES之中。
spider1处理京东建材主页:
spider2:处理京东分页栏:
spider3:处理京东列表:
spider4:处理产品详情:
根据上面的框架图。我们发现每一个spider都需要跟MQ链接,第一级的Spider不需要对MQ进行消费,最后一级的Spider不需要负责Mq数据的生产。 其他的spider既需要对MQ进行消费,也需要对MQ进行生产。
因此我们给没一个spider都绑上一个消费者和生产者,框架示意图如下:

WebMagic作为一款优秀爬虫框架,拓展性良好,我们在原先的框架上稍作拓展。
我们在原先的webMagic spider基础上添加一个异步的消费者consumer(consumer封装了rabbitMq的消费操作,比较简单就不附代码),它的作用:
- 负责读取MQ中待消费的信息,并将需要爬取数据添加的spider的requestList。
- 记录所有读取到消息。当spider消费完这段消息后,返回消息的ack给MQ,表示消息已经被成功消费。
- 读取queue中的消息剩余量,作为关闭spider的条件之一
附上代码:
spider基础上添加一个父级的spider,它的作用:
- 配合consumer读取消息剩余量关闭spider。如果父级的spider不存在或者已经关闭,当前spider已经消费完毕,queue中也没有剩余的消息。当前的spider就可以关闭了
1 package com.chinaredstar.jc.core.spider; 2 3 import com.chinaredstar.jc.core.page.CrawlerPage; 4 import com.chinaredstar.jc.crawler.consumer.Consumer; 5 import com.chinaredstar.jc.infras.utils.JSONUtil; 6 import com.rabbitmq.client.QueueingConsumer; 7 import org.apache.commons.collections.map.HashedMap; 8 import us.codecraft.webmagic.Request; 9 import us.codecraft.webmagic.Spider; 10 import us.codecraft.webmagic.SpiderListener; 11 import us.codecraft.webmagic.processor.PageProcessor; 12 13 import java.io.IOException; 14 import java.util.ArrayList; 15 import java.util.Map; 16 17 18 /** 19 * @author zhuangj 20 * @date 2017/12/1 21 */ 22 public class JcSpider extends Spider { 23 24 /** 25 * 队列消费者,为spider提供数据 26 */ 27 private Consumer consumer; 28 29 /** 30 * 队列消费者,为spider提供数据 31 */ 32 private String consumerQueueName; 33 34 /** 35 * 用于确认Mq中的消息是否执行完毕 36 */ 37 private Map<String,QueueingConsumer.Delivery> ackMap=new HashedMap(); 38 39 /** 40 * 剩余消息数量 41 */ 42 private Integer messageNum=0; 43 44 /** 45 * 父节点爬虫,父节点停止,子节点才能停止 46 */ 47 private JcSpider parentSpider; 48 49 50 public JcSpider(PageProcessor pageProcessor) { 51 super(pageProcessor); 52 exitWhenComplete=false; 53 } 54 55 public Consumer getConsumer() { 56 return consumer; 57 } 58 59 public void setConsumer(Consumer consumer) { 60 this.consumer = consumer; 61 } 62 63 public JcSpider getParentSpider() { 64 return parentSpider; 65 } 66 67 public void setParentSpider(JcSpider parentSpider) { 68 this.parentSpider = parentSpider; 69 } 70 71 72 public Integer getMessageNum() { 73 return messageNum; 74 } 75 76 public void setMessageNum(Integer messageNum) { 77 this.messageNum = messageNum; 78 } 79 80 public String getConsumerQueueName() { 81 return consumerQueueName; 82 } 83 84 public void setConsumerQueueName(String consumerQueueName) { 85 this.consumerQueueName = consumerQueueName; 86 } 87 88 @Override 89 protected void initComponent() { 90 super.initComponent(); 91 this.setSpiderListeners(new ArrayList<>()); 92 this.requestMessageListen(); 93 // this.startConsumer(consumerQueueName); 94 } 95 96 public void startConsumer(String queueName) { 97 if(consumer==null){ 98 this.exitWhenComplete=true; 99 return;100 }101 logger.info("queueName:{},startConsumer",queueName);102 JcSpider jcSpider = this;103 Runnable myRunnable = () -> {104 try {105 messageNum=consumer.getQueueMsgNum(queueName);106 107 Status parentStatus = Status.Stopped;108 if(parentSpider!=null){109 parentStatus=parentSpider.getStatus();110 }111 112 while (!parentStatus.equals(Status.Stopped) || messageNum > 0) {113 if(!jcSpider.getStatus().equals(Status.Running)){114 Thread.sleep(500);115 }116 QueueingConsumer.Delivery delivery = consumer.getDeliveryMessage(queueName);117 String message = new String(delivery.getBody());118 CrawlerPage crawlerPage = JSONUtil.toObject(message, CrawlerPage.class);119 Request request = crawlerPage.translateRequest();120 121 //添加监听122 ackMap.put(request.getUrl(),delivery);123 jcSpider.addRequest(request);124 messageNum=consumer.getQueueMsgNum(queueName);125 if(messageNum==0){126 Thread.sleep(500);127 }128 }129 System.out.println("spider:"+getUUID()+",consumer stop");130 if(parentSpider!=null){131 System.out.println("parentStatus:"+parentSpider.getStatus().name());132 }133 System.out.println("messageNum:"+messageNum);134 //父级没有消息,消息队列没有消息,爬虫完成后就退出了135 Thread.sleep(2000);136 this.exitWhenComplete=true;137 } catch (Exception e) {138 e.printStackTrace();139 }140 };141 Thread thread = new Thread(myRunnable);142 thread.start();143 }144 145 146 /**147 * 添加请求RequestMessage148 */149 private void requestMessageListen(){150 this.getSpiderListeners().add(new SpiderListener() {151 @Override152 public void onSuccess(Request request) {153 ackMq(request);154 }155 @Override156 public void onError(Request request) {157 ackMq(request);158 }159 });160 }161 162 public void ackMq(Request request){163 try {164 QueueingConsumer.Delivery delivery=ackMap.get(request.getUrl());165 if(delivery!=null){166 consumer.ackMessage(delivery);167 ackMap.remove(request.getUrl());168 }169 } catch (IOException e) {170 e.printStackTrace();171 }172 }173 174 175 }
spider根据级别添加MqPipeline或者EsPipeline,将处理后的数据添加到MQ或者ES之中:
package com.chinaredstar.jc.core.pipeline;import com.chinaredstar.jc.core.page.CrawlerPage;import com.chinaredstar.jc.crawler.producer.Producer;import com.chinaredstar.jc.infras.utils.JSONUtil;import org.apache.commons.collections4.CollectionUtils;import us.codecraft.webmagic.ResultItems;import us.codecraft.webmagic.Task;import us.codecraft.webmagic.pipeline.Pipeline;import java.io.IOException;import java.util.List;/** * 消息队列pipeline * @author zhuangj * @date 2017/12/1 */public class MqPipeline implements Pipeline { private Producer producer; public MqPipeline(Producer producer) { this.producer = producer; } public Producer getProducer() { return producer; } public void setProducer(Producer producer) { this.producer = producer; } @Override public void process(ResultItems resultItems, Task task) { try { List<CrawlerPage> crawlerPageList= resultItems.get("nextPageList"); if(CollectionUtils.isEmpty(crawlerPageList)){ return; } for(CrawlerPage page:crawlerPageList){// System.out.println("into MQ:"+JSONUtil.toJSonString(page)); producer.basicPublish(JSONUtil.toJSonString(page)); } } catch (IOException e) { e.printStackTrace(); } }}
package com.chinaredstar.jc.core.pipeline;import com.chinaredstar.jc.core.es.EsConnectionPool;import com.chinaredstar.jc.infras.utils.json.JsonFormatter;import org.elasticsearch.action.admin.indices.create.CreateIndexRequest;import org.elasticsearch.action.admin.indices.exists.indices.IndicesExistsRequest;import org.elasticsearch.action.admin.indices.exists.indices.IndicesExistsResponse;import org.elasticsearch.action.bulk.BulkRequestBuilder;import org.elasticsearch.action.bulk.BulkResponse;import org.elasticsearch.action.index.IndexRequestBuilder;import org.elasticsearch.client.transport.TransportClient;import org.elasticsearch.common.xcontent.XContentType;import us.codecraft.webmagic.ResultItems;import us.codecraft.webmagic.Task;import us.codecraft.webmagic.pipeline.Pipeline;import java.io.IOException;import java.net.UnknownHostException;/** * Created by zhuangj on 2017/12/1. */public class EsPipeline implements Pipeline { private String taskName; private EsConnectionPool pool=new EsConnectionPool(3); public EsPipeline(String taskName) { this.taskName=taskName; } @Override public void process(ResultItems resultItems, Task task) { try { TransportClient client=pool.get(); this.createIndex(client,taskName); this.insertData(client,taskName,"crawler",null, JsonFormatter.toJsonAsString(resultItems.getAll()));// System.out.println("save ES:" + JsonFormatter.toJsonAsString(resultItems.getAll())); pool.returnToPool(client); } catch (IOException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } } /** * 创建索引 */ private boolean createIndex(TransportClient client,String index) { try { if (isIndexExist(client,index)) { return true; } client.admin().indices().create(new CreateIndexRequest(index)).actionGet(); return true; }catch (Exception e){ return false;注:本文内容来自互联网,旨在为开发者提供分享、交流的平台。如有涉及文章版权等事宜,请你联系站长进行处理。