

一、前言
消息队列中间件(简称消息中间件)是指利用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。
通过提供消息传递和消息排队模型,它可以在分布式环境下提供应用解耦、弹性伸缩、冗余存储、流量削峰、异步通信、数据同步等等功能,其作为分布式系统架构中的一个重要组件,有着举足轻重的地位。
目前开源的消息中间件有ActiveMQ、RabbitMQ、Kafka、RocketMQ、pulsar等,在整体架构中引入消息中间件,势必要考虑很多因素,比如成本及收益问题,怎么样才能达到最优的性价比?虽然消息中间件种类繁多,但是各自都有各自的侧重点,选择合适自己、扬长避短无疑是最好的方式。
二、介绍
以下列出了目前比较主流的消息中间件的简单对比 (本文主要针对kafka和RabbitMQ作详细介绍)
消息中间件模型
-
点对点模型
点对点模型用于消息生产者和消息消费者之间点到点的通信。消息生产者将消息发送到由某个名字标识的特定消费者。这个名字实际上对于消费服务中的一个队列(
Queue),在消息传递给消费者之前它被存储在这个队列中。队列消息可以放在内存中也可以持久化,以保证在消息服务出现故障时仍然能够传递消息。每个消息只有一个消费者,不可重复消费(一旦被消费,消息就不再在消息队列中)
-
发布/订阅模型
类似微信公众号,用户关注之后,公众号系统(发布者)就会发布消息,用户的微信就会收到推送的消息,这边还需要区分pull(拉取)和push(推送)
-
pull:主动权在于消费方,优点是按需消费(吃自助餐,能吃多少拿多少),而且服务端队列堆积的消息处理也相对简单(不用记录状态啊,状态都在消费端);缺点就是消息延迟(不知道啥时候去拉取更新);当然也可以根据实际情况来选择和push组合起来用来提高消息的实时性 -
push:主动权就在服务方了,优点是实时性高,服务端可以统一管理来进行负载,不过也容易导致慢消费;缺点就是发送消息的状态是集中式管理,压力大(要分发消息还要记录状态还要做备份)
-
基本概念
kafka
Broker
broker指一个kafka服务器,如果多个broker形成集群会依靠Zookeeper集群进行服务的协调管理。
生产者发送消息给Kafka服务器。消费者从Kafka服务器读取消息。
Topic和Partition
topic代表了一类消息,也可以认为是消息被发送到的地方。通常我们可以使用topic来区分实际业务,比如业务A使用一个topic,业务B使用另外一个topic。
Kafka中的topic通常都会被多个消费者订阅,因此出于性能的考量,Kafka并不是topic-message的两级结构,而是采用了topic-partition-message的三级结构来分散负载。从本质上说,每个Kafka topic都由若干个partition组成
如图:topic是由多个partition组成的,而Kafka的partition是不可修改的有序消息序列,也可以说是有序的消息日志。每个partition有自己专属的partition编号,通常是从0开始的。用户对partition唯一能做的操作就是在消息序列的尾部追加写入消息。partition上的每条消息都会被分配一个唯一的序列号
该序列号被称为位移(offset)是从0开始顺序递增的整数。位移信息可以唯一定位到某partition下的一条消息。
kafka为什么要设计分区?
解决伸缩性的问题。假如一个broker积累了太多的数据以至于单台Broker机器都无法容纳了,此时应该怎么办呢?一个很自然的想法就是,能否把数据分割成多份保存在不同的Broker上?所以kafka设计了分区。
消费者组
Consumer Group是指组里面有多个消费者或消费者实例,它们共享一个公共的ID,这个ID被称为Group ID。组内的所有消费者协调在一起来消费订阅主题topic的所有分区(Partition)。每个分区只能由同一个消费者组内的一个Consumer实例来消费。
Consumer Group三个特性。
- Consumer Group下可以有一个或多个Consumer实例。
- Group ID是一个字符串,在一个Kafka集群中,它标识唯一的一个Consumer Group。
- Consumer Group下所有实例订阅的主题的单个分区,只能分配给组内的某个Consumer实例消费。这个分区 当然也可以被其他的Group消费。
还记得上面提到的两种消息中间件模型
Kafka 仅仅使用Consumer Group这一种机制,却同时实现了传统消息引擎系统的两大模型:如果所有实例都属于同一个Group,那么它实现的就是点对点模型;如果所有实例分别属于不同的Group,那么它实现的就是发布/订阅模型。
在实际使用场景中,一个Group下该有多少个Consumer实例呢?
理想情况下,Consumer实例的数量应该等于该Group订阅主题的分区总数。
举个简单的例子,假设一个Consumer Group订阅了3个主题,分别是 A、B、C,它们的分区数依次是 1、2、3, 那么通常情况下,为该Group设置1+2+3=6个Consumer实例是比较理想的情形,因为它能最大限度地实现高伸缩性。
消费顺序问题
按照上面的设计,可能会导致消费顺序问题,下面一一介绍
乱序场景一
因为一个topic可以有多个partition,kafka只能保证partition内部有序
当partition数量=同一个消费者组中消费者数量时,可能需要顺序的数据分布到了不同的partition,导致处理时乱序
解决方案
-
可以设置topic有且只有一个partition
-
根据业务需要,需要顺序的指定为同一个partition
乱序场景二
对于同一业务进入了同一个消费者组之后,用了多线程来处理消息,会导致消息的乱序
解决方案
消费者内部根据线程数量创建等量的内存队列,对于需要顺序的一系列业务数据,根据key或者业务数据,放到同一个内存队列中,然后线程从对应的内存队列中取出并操作
Rebalance
Rebalance本质上是一种协议,规定了一个Consumer Group下的所有Consumer如何达成一致,来分配订阅Topic的每个分区。比如某个Group下有20个Consumer实例,它订阅了一个具有100个分区的Topic。正常情况下,Kafka平均会为每个Consumer分配5个分区。这个分配的过程就叫Rebalance。
Consumer Group何时进行Rebalance呢?Rebalance的触发条件有3个。
- **组成员数发生变更。**比如有新的Consumer实例加入组或者离开组,或是有Consumer实例崩溃被"踢出"组。
- **订阅主题数发生变更。**Consumer Group可以使用正则表达式的方式订阅主题,比如
consumer.subscribe(Pattern.compile(“t.*c”))就表 明该Group订阅所有以字母t开头、字母c结尾的主 题。在Consumer Group的运行过程中,你新创建了一个满足这样条件的主题,那么该Group就会发生 Rebalance。 - **订阅主题的分区数发生变更。**Kafka当前只能允许增加一个主题的分区数。当分区数增加时,就会触发订阅该主题的所有Group开启Rebalance。
Rebalance过程对Consumer Group消费过程有极大的影响。会stop the world,简称 STW。我们知道在 STW 期间,所有应用线程都会停止工作,表现为整个应用程序僵在那边一动不动。Rebalance过程也和这个类似,在Rebalance过程中,所有Consumer实例都会停止消费,等待Rebalance完成。这是Rebalance为人诟病的一个方面。
存储原理
Broker存储模型分析
一个Topic是如何存储到多个Broker中的呢?由上图,我们可以知道,Topic 1分成了3个Partition分别是P1、P2、P3。
而且每个Partition还设置了2个副本。
上图中,红色背景的P1是Partition1的leader分区,蓝色背景的P1是follower分区。消费者读取数据只通过leader节点来进行,这样就避免了主从复制带来的数据一致性问题。
Replica副本分析
既然我们己知partition是有序消息日志,那么一定不能只保存这一份日志,否则一旦保存partition的Kafka服务器挂掉了,其上保存的消息也就都丢失了。分布式系统必然要实现高可靠性,而目前实现的主要途径还是依靠冗余机制,通过备份多份日志 。这些备份日志在Kafka中被称为副本(replica),它们存在的唯一目的就是防止数据丢失
- 副本分布:
-
首先,副本因子不能大于Broker的个数;
-
第一个分区(编号为0的分区)的第一个副本放置位置是随机从 broker集合选择的;
-
其他分区的第一个副本放置位置相对于第0个分区依次往后移;举例:如果我们有3个Broker,4个分区,假设第1个分区的第1个副本放在第一个Broker上,那么第2个分区的第1个副本将会放在第二个 Broker 上;第三个分区的第1个副本将会放在第三个Broker 上;第四个分区的第1个副本将会放在第一Broker 上,依次类推;
-
每个分区剩余的副本相对于第1个副本放置位置其实是由
nextReplicaShift决定的,而这个数也是随机产生的。
-
副本分类 :
领导者副本( leader replica )和追随者副本( follower replica )。
follower replica是不能提供服务给客户端的,也就是说不负责响应客户端发来的消息写入和消息消费请求。它只是被动地向领导者副本( leader replica )获取数据,而一旦leader replica所在的broker宕机,Kafka 会从剩余的replica中选举出新的leader继续提供服务。
Leader和Follower
前面说的,Kafka的replica分为两个角色:领导者(leader)和追随者(follower)。Kafka保证同一个partition的多个replica一定不会分配在同一台broker上。毕竟如果同一个broker上有同一个partition的多个 replica,那么将无法实现备份冗余的效果。
-
副本选举:
所有的Broker启动时会尝试在Zookeeper中创建临时节点/Controller,只有一个能创建成功(先到先得)。如果Controller挂掉了或者网络出现了问题,Zookeeper上的临时节点会消失。其他的Broker通过watch监听到Controller下线的消息后,开始竞选新的Controller。方法跟之前还是一样的,谁先在Zookeeper里面写入一个Controller节点,谁就成为新的Controller。
Controller的作用?
有了Controller的Broker节点,就可以进行分区副本的leader的选举了。这里需要知道如下几个概念
- Assigned-Replicas (AR):是一个分区所有的副本。
- In-Sync Replicas(ISR) :是这些所有的副本中,跟leader数据保持一定程度同步的。
- Out-Sync-Replicas (OSR):是跟leader同步滞后过多的副本。
AR=ISR+OSR。正常情况下OSR是空的,大家都正常同步,AR=ISR。如果同步延迟超过30秒,就踢出ISR,进入OSR;如果赶上来了,就加入ISR。
leader副本如何选举呢?
这里是选举通过Controller来主持,使用微软的PacificA算法。在这种算法中,默认是让ISR中第一个replica变成leader。比如ISR是1、5、9,优先让1成为leader。
-
副本同步机制:
leader副本选举成功以后,就需要把数据同步给备份的的副本。follower是怎么想leader同步数据的呢?
首先我需要学习几个概念,如下图所示
- Hight Watermark(HW):副本水位值,表示分区中最新一条已提交(Committed)的消息的Offset。
- LEO:Log End Offset,Leader中最新消息的Offset。
- Committed Message:已提交消息,已经被所有ISR同步的消息。
- Lagging Message:没有达到所有ISR同步的消息。
数据同步过程是什么样的呢?
- follower节点会向leader发送一个fetch请求,leader向follower发送数据后,既需要更新follower的 LEO。
- follower接收到数据响应后,依次写入消息并且更新LEO。
- leader更新HW (ISR最小的LEO)。
注意,消费者只能消费在HW的数据。kafka设计了独特的ISR复制,可以在保障数据一致性情况下又可提供高吞吐量。
故障如何处理?
-
follower故障
如果follower发生了故障,会进行如下步骤的操作
- follower被踢出ISR。
- follower恢复以后,根据之前记录的HW,把高于HW的数据删除。
- 然后同步leader的数据,直到追上leader,重新加入ISR。
-
leader故障
如果leader发生了故障,会进行如下步骤的操作
- leader被踢出ISR,Controller重新选举一个leader出来。
- 其他follower删除高于HW的消息,然后同步leader的数据。
**注意:**这种机制只能保证数据的一致性,不能保证数据的丢失和重复。
segment分析
为了防止log不断追加导致文件过大,导致检索消息效率变低,一个partition又被划分成多个segment来存储数据(MySQL也有segment的逻辑概念,叶子节点就是数据段,非叶子节点就是索引段)。
- segment文件结构分析
每个partition里面文件都有如下图中的一套文件(3个):
.log文件就是存储消息的文件。.index是偏移量(offset)索引文件。.timeindex是时间戳(timestamp)索引文件。
.log文件在消息发送不断追加数据的过程中,满足一定的条件就会进行日志切分,产生一套新的segment文件。切分日志的条件如下:
第一种情况:根据.log文件的大小判断,可以通过如下参数控制,默认值是1073741824 byte (1G)
log.segment.bytes=1073741824
第二种情况:根据消息的最大时间戳,和当前系统时间戳的差值。可以通过如下参数控制,默认值168小时(一周)
log.roll.hours=168
# 可以用毫秒控制,参数如下
log.roll.ms
第三种情况:offset索引文件或者timestamp索引文件达到了一定的大小,默认是10485760字节(10M)。如果要减少日志文件的切分,可以把这个值调大一点。
log.index.size.max.bytes=10485760
-
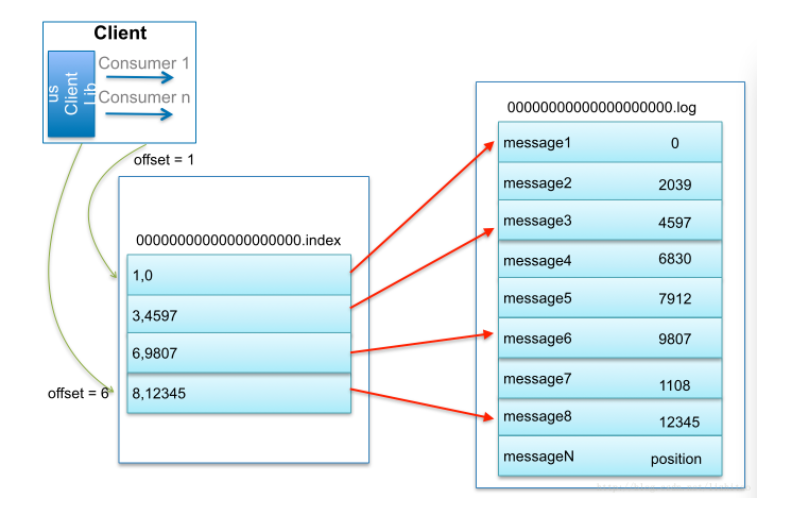
偏移量(offset)索引文件
偏移量索引文件记录的是 offset和消息物理地址(在log文件中的位置)的映射关系。内容是二级制文件。可以通过如下命令查看
./kafka-dump-log.sh --files /data/kafka-logs/cluster-test4java-2/00000000000000000000.index | head -n 10
注意kafka的索引并不是每一条消息都会建立索引,而是一种稀疏索引sparse index。稀疏索引结构如下图所示
稀疏索引的稀疏程度,是怎么来确定的呢?
偏移量索引的稀疏程度是有中间间隔消息的大小来确定,默认是4KB,可以由下面的参数控制
log.index.interval.bytes=4096
只要写入消息超过4K,则偏移量索引增加一条记录。
-
时间戳索引文件
时间戳索引有两种,一种是消息创建的时间戳,一种是消费在Broker追加写入的时间。到底用哪个时间呢?由一个参数来控制:
# 默认是消息创建时间(CreateTime),LogAppendTime是日志追加时间 log.message.timestamp.type=CreateTime或LogAppendTime查看最早的10条时间戳索引,命令入如下:
./kafka-dump-log.sh --files /data/kafka-logs/cluster-test4java-2/00000000000000000000.timeindex | head -n 10查看结果如下,这里记录的是时间和偏移量之间的映射关系
如何快速检索到消息?
比如我要检索偏移量是10002673的消息。
- 消费的时候是能够确定分区的,所以第一步是找到在哪个segment 中。Segment文件是用base offset命名的,所以可以用二分法很快确定(找到名字不小于10002673的segment)。
- 这个segment有对应的索引文件,它们是成套出现的。所以现在要在索引文件中根据offset找position。
- 得到position之后,到对应的log文件开始查找offset,和消息的offset进行比较,直到找到消息
总结:
kafka速度快的原因?
- 磁盘顺序写(数据)
- 零拷贝 (读数据)
- 文件索引(segment的
.index、.timeindex) - 消息批量读写和压缩,减少网络IO的损耗。
RabbitMQ
ConnectionFactory、Connection、Channel
ConnectionFactory、Connection、Channel
ConnectionFactory、Connection、Channel都是RabbitMQ对外提供的API中最基本的对象。
- ConnectionFactory:Connection的制造工厂。
- Connection:RabbitMQ的socket链接,它封装了socket协议相关部分逻辑。
- Channel(信道):信道是建立在“真实的”TCP连接上的虚拟连接,在一条TCP链接上创建多少条信道是没有限制的,把他想象成光纤就是可以了。它是我们与RabbitMQ打交道的最重要的一个接口,我们大部分的业务操作是在Channel这个接口中完成的,包括定义Queue、定义Exchange、绑定Queue与Exchange、发布消息等。
Queue(队列)
Queue是RabbitMQ的内部对象,用于存储消息。
RabbitMQ中的消息只能存储在Queue中。生产者(下图中的P)生产消息并最终投递到Queue中,消费者(下图中的C)可以从Queue中获取消息并消费,消费者可以是一个或者多个。
Message acknowledgment(ack 消息的确认):
在实际应用中,可能会发生消费者收到Queue中的消息,但没有处理完成就宕机(或出现其他意外)的情况,这种情况下就可能会导致消息丢失。为了避免这种情况发生,我们可以要求消费者在消费完消息后发送一个回执给RabbitMQ,RabbitMQ收到消息回执(ack)后才将该消息从Queue中移除;如果RabbitMQ没有收到回执并检测到消费者的RabbitMQ连接断开,则RabbitMQ会将该消息发送给其他消费者(如果存在多个消费者)进行处理。这里不存在timeout概念,一个消费者处理消息时间再长也不会导致该消息被发送给其他消费者,除非它的RabbitMQ连接断开。
这里会产生另外一个问题,如果我们的开发人员在处理完业务逻辑后,忘记发送回执给RabbitMQ,这将会导致严重的bug——Queue中堆积的消息会越来越多;消费者重启后会重复消费这些消息并重复执行业务逻辑
另外pub message是没有ack的。
Message durability(消息的持久化)
如果我们希望即使在RabbitMQ服务重启的情况下,也不会丢失消息,我们可以将Queue与Message都设置为可持久化的(durable),这样可以保证绝大部分情况下我们的RabbitMQ消息不会丢失。但依然解决不了小概率丢失事件的发生(比如RabbitMQ服务器已经接收到生产者的消息,但还没来得及持久化该消息时RabbitMQ服务器就断电了),如果我们需要对这种小概率事件也要管理起来,那么我们就要用到事务。
简单讲讲事务
RabbitMQ为我们提供了两种方式:
- 通过AMQP事务机制实现,这也是AMQP协议层面提供的解决方案;
- 通过将channel设置成confirm模式来实现;
-
AMQP事务机制实现
RabbitMQ中与事务机制有关的方法有三个:txSelect()、txCommit()以及txRollback(),txSelect用于将当前channel设置成transaction模式,txCommit用于提交事务,txRollback用于回滚事务,在通过txSelect开启事务之后,我们便可以发布消息给broker代理服务器了,如果txCommit提交成功了,则消息一定到达了broker了,如果在txCommit执行之前broker异常崩溃或者由于其他原因抛出异常,这个时候我们便可以捕获异常通过txRollback回滚事务了。
实现步骤:
- client发送Tx.Select
- broker发送Tx.Select-Ok(之后publish)
- client发送Tx.Commit
- broker发送Tx.Commit-Ok
事务确实能够解决producer与broker之间消息确认的问题,只有消息成功被broker接受,事务提交才能成功,否则我们便可以在捕获异常进行事务回滚操作同时进行消息重发,但是使用事务机制的话会降低RabbitMQ的性能,第二种方式可以有效降低性能损失。
-
confirm模式实现
上面我们介绍了RabbitMQ可能会遇到的一个问题,即生产者不知道消息是否真正到达broker,随后通过AMQP协议层面为我们提供了事务机制解决了这个问题,但是采用事务机制实现会降低RabbitMQ的消息吞吐量,那么有没有更加高效的解决方式呢?答案是采用Confirm模式。
confirm模式最大的好处在于他是异步的,一旦发布一条消息,生产者应用程序就可以在等信道返回确认的同时继续发送下一条消息,当消息最终得到确认之后,生产者应用便可以通过回调方法来处理该确认消息,如果RabbitMQ因为自身内部错误导致消息丢失,就会发送一条nack消息,生产者应用程序同样可以在回调方法中处理该nack消息。
在channel被设置成confirm模式之后,所有被publish的后续消息都将被confirm(即ack)或者被nack一次。但是没有对消息被confirm的快慢做任何保证,并且同一条消息不会既被confirm又被nack 。
Prefetch count(每次向消费者发送消息的总数)
前面我们讲到如果有多个消费者同时订阅同一个Queue中的消息,Queue中的消息会被平摊给多个消费者。这时如果每个消息的处理时间不同,就有可能会导致某些消费者一直在忙,而另外一些消费者很快就处理完手头工作并一直空闲的情况。我们可以通过设置prefetchCount来限制Queue每次发送给每个消费者的消息数,比如我们设置prefetchCount=1,则Queue每次给每个消费者发送一条消息;消费者处理完这条消息后Queue会再给该消费者发送一条消息。
Exchange(交换器)
Exchange生产者将消息发送到Exchange(交换器,下图中的X),由Exchange根据一定的规则将消息路由到一个或多个Queue中(或者丢弃)。
Routing key(路由key)
生产者在将消息发送给Exchange的时候,一般会指定一个routing key,来指定这个消息的路由规则。Exchange会根据routing key和Exchange Type(交换器类型)以及Binding key的匹配情况来决定把消息路由到哪个Queue。RabbitMQ为routing key设定的长度限制为255 bytes。
Binding(绑定)
RabbitMQ中通过Binding将Exchange与Queue关联起来。
Binding key
在绑定(Binding)Exchange与Queue关系的同时,一般会指定一个binding key。
Exchange Types (交换器类型)
RabbitMQ常用的Exchange Type有 Fanout、Direct、Topic、Headers这四种。
- Fanout这种类型的Exchange路由规则非常简单,它会把所有发送到该Exchange的消息路由到所有与它绑定的Queue中,这时Routing key不起作用。
- Direct这种类型的Exchange路由规则也很简单,它会把消息路由到那些binding key与routing key完全匹配的Queue中。
在这个设置中,我们可以看到两个队列Q1、Q2直接绑定到了交换器X上。第一个队列用绑定key橙色(orange)绑定,第二个队列有两个绑定,一个绑定key为黑色(black),另一个为绿色(green)。
在这种设置中,通过路由键橙色发布到交换器的消息将被路由到队列Q1。带有黑色或绿色的路由键的消息将进入Q2。所有其他消息将被丢弃。
在上面列子中,routingKey=”error”的消息发送Exchange后,Exchange会将消息路由到Queue1(amqp.gen-S9b…,这是由RabbitMQ自动生成的Queue名称)和Queue2(amqp.gen-Agl…);如果routingKey=”info”或routingKey=”warning”的消息发到Exchange,Exchange只会将消息路由到Queue2。所有其他消息将被丢弃。
- Topic 这种类型的Exchange的路由规则支持binding key和routing key的模糊匹配,会把消息路由到满足条件的Queue。binding key中可以存在两种特殊字符 *与 #,用于做模糊匹配,其中 * 用于匹配一个单词,#用于匹配0个或多个单词,单词以符号“.”为分隔符。
以上图中的配置为例,routingKey=”quick.orange.rabbit”的消息会同时路由到Q1与Q2,routingKey=”lazy.orange.fox”的消息会路由到Q1与Q2,routingKey=”lazy.brown.fox”的消息会路由到Q2,routingKey=”lazy.pink.rabbit”的消息会路由到Q2(只会投递给Q2一次,虽然这个routingKey与Q2的两个bindingKey都匹配);routingKey=”quick.brown.fox”、routingKey=”orange”、routingKey=”quick.orange.male.rabbit”的消息将会被丢弃,因为它们没有匹配任何bindingKey。
- Headers 这种类型的Exchange不依赖于routing key与binding key的匹配规则来路由消息,而是根据发送的消息内容中的headers属性进行匹配。
RPC
MQ本身是基于异步的消息处理,前面的示例中所有的生产者(P)将消息发送到RabbitMQ后不会知道消费者(C)处理成功或者失败(甚至连有没有消费者来处理这条消息都不知道)。 但实际的应用场景中,我们很可能需要一些同步处理,需要同步等待服务端将我的消息处理完成后再进行下一步处理。这相当于RPC(Remote Procedure Call,远程过程调用)。在RabbitMQ中也支持RPC。
RabbitMQ中实现RPC的机制是:
- 客户端发送请求(消息)时,在消息的属性中(MessageProperties,在AMQP协议中定义了14中properties,这些属性会随着消息一起发送)设置两个值replyTo(一个Queue名称,用于告诉服务器处理完成后将通知我的消息发送到这个Queue中)和correlationId(此次请求的标识号,服务器处理完成后需要将此属性返还,客户端将根据这个id了解哪条请求被成功执行了或执行失败)
- 服务器端收到消息并处理
- 服务器端处理完消息后,将生成一条应答消息到replyTo指定的Queue,同时带上correlationId属性 客户端之前已订阅replyTo指定的Queue,从中收到服务器的应答消息后,根据其中的correlationId属性分析哪条请求被执行了,根据执行结果进行后续业务处理
三、应用场景
-
系统解耦(发布/订阅模式)
A系统需要发送数据到B/C/D三个系统,通过接口调用发送;
如果E系统也需要数据,C系统又不要了,那这样A系统的人疯掉,业务需求变化太快
如果使用了消息系统,可以做到A系统只需要发送数据到MQ,需要数据的系统就去订阅MQ中的topic即可
2. 异步消息
A系统收到请求,需要本地写库,还需要再BCD三个系统写库,A系统本地写库耗时20ms,B耗时300ms,C耗时450ms,D耗时200ms,最终延时20+300+450+200=970ms,用户收到最终回复需要将近1s,太慢了(一般互联网企业用户请求时间需要在200ms以内)。
使用消息系统之后,A只需要将消息丢到BCD系统对应的MQ队列中,A本地写库完成之后即可返回给用户,耗时20ms,加上A发消息到MQ的时间5ms,总时长25ms用户就可以收到请求回复;
3. 流量削峰
每天0点到12点,A系统风平浪静,并发请求50/s,但是一到中午12点-13点之间,并发徒增,达到5k+/s,但是系统是基于MySql的,大量请求涌入MySql,5k/s的请求会直接把MySql搞崩溃;
一般MySql最多2k/s请求,所以需要MQ来作为中转站,A系统从MQ中拉取请求2k/s存到MySql中,这个压力MySql可以抗住,但是这样一来MQ中的消息会越压越多,中午12点-13点这一个小时的MQ压力会很大,消息堆积会很多,不过这种积压是ok的,高峰期一过,A系统继续以2k/s的速度处理消息,MQ在过了高峰期之后就不会有太多的消息继续堆积进来,A系统以最大处理能力处理MQ中的数据,很快就可以全部解决掉,这就是通过MQ来进行削峰处理
四、性能对比
简单对比
应用方面
- RabbitMQ采用Erlang语言实现的AMQP协议的消息中间件,最初起源于金融系统,用于在分布式系统中存储转发消息。RabbitMQ发展到今天,被越来越多的人认可,这和它在可靠性、可用性、扩展性、功能丰富等方面的卓越表现是分不开的。
- Kafka起初是由LinkedIn公司采用Scala语言开发的一个分布式、多分区、多副本且基于zookeeper协调的分布式消息系统,现已捐献给Apache基金会。它是一种高吞吐量的分布式发布订阅消息系统,以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、ApacheStorm、Spark、Flink等都支持与Kafka集成。
架构模型方面
- RabbitMQ遵循
AMQP协议,RabbitMQ的broker由Exchange、Binding、queue组成,其中exchange和binding组成了消息的路由键;客户端Producer通过连接channel和server进行通信,Consumer从queue获取消息进行消费(长连接,queue有消息会推送到consumer端,consumer循环从输入流读取数据)。RabbitMQ以broker为中心;有消息的确认机制。 - Kafka遵从一般的MQ结构,producer、broker、consumer,以consumer为中心,消息的消费信息保存的客户端consumer上,consumer根据消费的点,从broker上批量pull数据;无消息确认机制。
吞吐量
- RabbitMQ在吞吐量方面稍逊于Kafka,他们的出发点不一样,RabbitMQ支持对消息的可靠的传递,支持事务,不支持批量的操作;基于存储的可靠性的要求存储可以采用内存或者硬盘。
- Kafka具有高的吞吐量,内部采用消息的批量处理,零拷贝(zero-copy)机制,数据的存储和获取是本地磁盘顺序批量操作,具有O(1)的复杂度,消息处理的效率很高。
详细对比
RabbitMQ和Kafka两个中间件可以围绕可靠性和吞吐量来对比
可靠性
消息丢失包括三种情况:
- producer丢数据
- mq自己丢了
- consumer消费的时候丢了
rabbitmq
-
producer丢了
-
场景:producer发数据到rabbitmq,由于网络原因发送失败了。
-
处理:可以用rabbitmq的事务功能,producer发数据时开启事务(channel.txSelect),如果rabbitmq没收到,则回滚(channel.txRollback),然后重试;如果收到了,那就提交(channel.txCommit)。但是加了事务,吞吐量会下降,影响性能。还有一个confirm模式,producer每次发消息都会分配唯一的id,如果写入mq成功,则mq回传producer一个ack。如果mq没能处理这个消息,则回写nack,说明写入失败了,producer可以重试。
confirm模式与事务模式的区别在于,confirm模式是异步的,事务则是同步的。
-
-
mq自己丢了
-
场景:这种情况概率很小,除非在mq还没持久化的时候,自己就挂了,可能会导致少量数据丢失。
-
处理:持久化机制可以和confirm机制结合,mq在持久化成功之后才回写ack给producer,这样在持久化失败的时候,producer收不到ack,还可以重发。
-
-
consumer消费的时候丢了
-
场景:程序拿到了数据,还没处理,结果进程挂了,但是mq认为你消费过了。
-
处理:mq提供了ack机制,需要把自动ack关闭,等到程序处理完成之后,调用一个api实现回写ack,这样就可以保证程序处理完之后消息才是被消费的状态。
-
kafka
-
producer丢了
- 场景:当ack设置不是all时,可能会导致丢数据
- 处理:设置ack=all,leader收到消息之后,等所有follower同步之后,才会认为消息发成功
-
mq自己丢了
-
场景:kafka某个broker挂了,重新选举pratition的leader的时候,其他follower刚好还有数据未同步,但是leader挂了,所以会造成少量数据丢失
-
处理:topic设置replication.factor,这个值必须大于1,要求partition至少有两个以上副本
kafka服务端设置min.insync.replicas,这个值必须大于1,要求一个leader至少有一个follower跟自己保持联系,这样确保leader挂了的时候至少有一个follower保持数据同步
producer设置acks=all
producer设置retries=MAX,一旦写入失败就无限重试
-
-
consumer消费的时候丢了
- 场景:程序拿到了数据,还没处理,结果进程挂了,但是消费者自动提交了offset。mq认为你消费过了。
- 处理:跟rabbitmq类似,可以关闭自动提交offset,在程序处理完之后,在手动提交offset
吞吐量
服务器环境1C+2G,单机kafka+单机rabbitmq
kafka自带工具perf-test测试
-
生产者压力测试
Kafka消息写入测试
MQ消息数 每秒写入消息数 记录大小(单位:字节) 10W 2000条 1000 100W 5000条 2000 1000W 100000条 100 1000W 1000000条 100 写入测试信息
压力测试数 测试命令 10W ./kafka-producer-perf-test.sh--topictest_perf--num-records100000--record-size1000--throughput2000--producer-propsbootstrap.servers=192.168.244.130:9092 100W ./kafka-producer-perf-test.sh--topictest_perf--num-records1000000--record-size2000--throughput5000--producer-propsbootstrap.servers=192.168.244.130:9092 1000W(--throughput100000) ./kafka-producer-perf-test.sh--topictest_perf--num-records10000000--record-size100--throughput100000--producer-propsbootstrap.servers=192.168.244.130:9092 1000W(--throughput1000000) ./kafka-producer-perf-test.sh--topictest_perf--num-records10000000--record-size100--throughput1000000--producer-propsbootstrap.servers=192.168.244.130:9092
10W(每秒写入数--throughput2000),实际写入消息数1991records/sec,95%消息延时11ms
100W(每秒写入数--throughput5000),实际写入消息数4995records/sec,95%消息延时4ms
1000W(每秒写入数--throughput1000000),实际写入消息树221057records/sec,95%消息延时9455ms
1000W(每秒写入数--throughput1000000),实际写入消息树238027records/sec,95%消息延时1862ms
-
消费者压力测试
参数说明: --
bootstrap-server指定kafka地址 --topic指定topic的名称 --fetch-size指定每次fetch的数据的大小 --messages总共要消费的消息个数10w消费总数,执行命令: ./kafka-consumer-perf-test.sh--bootstrap-server192.168.244.130:9092--topictest_perf--fetch-size1000--messages100000--threads1 输出结果: start.time,end.time,data.consumed.in.MB,MB.sec,data.consumed.in.nMsg,nMsg.sec,rebalance.time.ms,fetch.time.ms,fetch.MB.sec,fetch.nMsg.sec 2021-06-2223:29:24:374,2021-06-2223:29:27:022,95.6879,36.1359,100168,37827.7946,817,1831,52.2599,54706.7176 2021-06-2223:30:41:019,2021-06-2223:30:43:394,95.6879,40.2896,100168,42176.0000,810,1565,61.1424,64005.1118 100w消费总数,执行命令: ./kafka-consumer-perf-test.sh--bootstrap-server192.168.244.130:9092--topictest_perf--fetch-size1048576--messages1000000--threads1 输出结果: start.time,end.time,data.consumed.in.MB,MB.sec,data.consumed.in.nMsg,nMsg.sec,rebalance.time.ms,fetch.time.ms,fetch.MB.sec,fetch.nMsg.sec 2021-06-2223:31:09:318,2021-06-2223:31:37:626,1812.8414,64.0399,1000451,35341.6349,1340,26968,67.2219,37097.7084 2021-06-2223:32:56:384,2021-06-2223:33:19:076,1812.8414,79.8890,1000451,44088.2690,1054,21638,83.7805,46235.8351 1000w消费总数,执行命令: ./kafka-consumer-perf-test.sh--bootstrap-server192.168.244.130:9092--topictest_perf--fetch-size1048576--messages10000000--threads1 输出结果: start.time,end.time,data.consumed.in.MB,MB.sec,data.consumed.in.nMsg,nMsg.sec,rebalance.time.ms,fetch.time.ms,fetch.MB.sec,fetch.nMsg.sec 2021-06-2223:34:22:717,2021-06-2223:35:02:586,2288.8184,57.4085,1400000,35115.0016,1038,38831,58.9431,36053.6685 2021-06-2223:35:32:720,2021-06-2223:36:10:933,2288.8184,59.8963,1400000,36636.7467,646,37567,60.9263,37266.7501总结:
消费消息总数(单位:w) 共消费数据(单位:M) 每秒消费数据(单位:M) 每秒消费消息数 10W 95.6879 36.1359 100168 100W 1812.8414 79.8890 1000451 1000W 2288.8184 59.8963 1400000
rabbitmq自带工具perf-test测试
1个生产者(-x1),1个消费者(-y1),生产者速率(-rate2000)./runjavacom.rabbitmq.perf.PerfTest-x1-y1-u"perf_test1"-a--id"hello1"-rate200095%延时1ms左右
1个生产者(-x1),1个消费者(-y1),生产者速率(-rate5000)./runjavacom.rabbitmq.perf.PerfTest-x1-y1-u"perf_test1"-a--id"hello1"-rate500095%延时大部分在1.6ms左右,偶尔会有较大波动出现7ms、285ms等
1个生产者(-x1),1个消费者(-y1)./runjavacom.rabbitmq.perf.PerfTest-x1-y1-u"perf_test1"-a--id"hello1"不限制速率,延时较大按图中所示,消息发布最大大约可达到29000msg/s左右
使用javademo测试
kafka代码如下
引入maven依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.6.0</version></dependency>
生产者代码
package com.epoint.demo.kafka;
import com.epoint.demo.Constants;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
/**
* Description:
*
* @author james
* @date 2021/6/21 13:54
*/
public class Producer
{
private final KafkaProducer<String, String> producer;
public Producer() {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.244.130:9092");
/*
* 发出消息持久化机制参数 (1)acks=0:
* 表示producer不需要等待任何broker确认收到消息的回复,就可以继续发送下一条消息。性能最高,但是最容易丢消息。 (2)acks=1:
* 至少要等待leader已经成功将数据写入本地log,但是不需要等待所有follower是否成功写入。就可以继续发送下一条消息。这种情况下,
* 如果follower没有成功备份数据,而此时leader 又挂掉,则消息会丢失。 (3)acks=-1或all:
* 这意味着leader需要等待所有备份(min.insync.replicas配置的备份个数)都成功写入日志,
* 这种策略会保证只要有一个备份存活就不会丢失数据。 这是最强的数据保证。一般除非是金融级别,或跟钱打交道的场景才会使用这种配置。
*/
properties.put(ProducerConfig.ACKS_CONFIG, "1");
// 发送失败会重试,默认重试间隔100ms,重试能保证消息发送的可靠性,但是也可能造成消息重复发送,比如网络抖动,所以需要在接收者那边做好消息接收的幂等性处理
properties.put(ProducerConfig.RETRIES_CONFIG, 3);
// 重试间隔设置
properties.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 300);
// 设置发送消息的本地缓冲区,如果设置了该缓冲区,消息会先发送到本地缓冲区,可以提高消息发送性能,默认值是33554432,即32MB
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
// kafka本地线程会从缓冲区取数据,批量发送到broker,
// 设置批量发送消息的大小,默认值是16384,即16kb,就是说一个batch满了16kb就发送出去
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
// 默认值是0,意思就是消息必须立即被发送,但这样会影响性能
// 一般设置100毫秒左右,就是说这个消息发送完后会进入本地的一个batch,如果100毫秒内,这个batch满了16kb就会随batch一起被发送出去
// 如果100毫秒内,batch没满,那么也必须把消息发送出去,不能让消息的发送延迟时间太长
properties.put(ProducerConfig.LINGER_MS_CONFIG, 100);
// 把发送的key从字符串序列化为字节数组
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 把发送消息value从字符串序列化为字节数组
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
producer = new KafkaProducer<>(properties);
}
public void producer() {
long start = System.currentTimeMillis();
for (int i = 0; i < Constants.COUNT_300000; i++) {
String data = Constants.MESSAGE_1 + i;
producer.send(new ProducerRecord<>(Constants.QUEUE, data),
(metadata, exception) -> System.out.println("发送成功,msg:" + metadata.offset()));
}
producer.close();
long end = System.currentTimeMillis();
System.out.println((end - start) + "ms");
}
public static void main(String[] args) {
new Producer().producer();
}
}
消费者代码
package com.epoint.demo.kafka;
import com.epoint.demo.Constants;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
/**
* Description:
*
* @author james
* @date 2021/6/21 13:43
*/
public class Consumer
{
public static void main(String[] args) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.244.130:9092");
// 消费分组名
props.put(ConsumerConfig.GROUP_ID_CONFIG, "testGroup");
// 是否自动提交offset
// props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// 自动提交offset的间隔时间
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
/*
* 心跳时间,服务端broker通过心跳确认consumer是否故障,如果发现故障,就会通过心跳下发
* rebalance的指令给其他的consumer通知他们进行rebalance操作,这个时间可以稍微短一点
*/
props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 1000);
// 服务端broker多久感知不到一个consumer心跳就认为他故障了,默认是10秒
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10 * 1000);
/*
* 如果两次poll操作间隔超过了这个时间,broker就会认为这个consumer处理能力太弱, 会将其踢出消费组,将分区分配给别的consumer消费
*/
props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 30 * 1000);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 消费主题
consumer.subscribe(Collections.singletonList(Constants.QUEUE));
// 消费指定分区
// consumer.assign(Arrays.asList(new TopicPartition(Constants.QUEUE, 0)));
// 消息回溯消费
// consumer.assign(Arrays.asList(new TopicPartition(Constants.QUEUE, 0)));
// consumer.seekToBeginning(Arrays.asList(new TopicPartition(Constants.QUEUE,
// 0)));
// 指定offset消费
// consumer.seek(new TopicPartition(topicName, 0), 10);
while (true) {
// 从服务器开始拉取数据
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
records.forEach(record -> {
System.out.printf("topic = %s ,partition = %d,offset = %d, key = %s, value = %s%n", record.topic(),
record.partition(), record.offset(), record.key(), record.value());
});
}
}
}
rabbitmq代码如下
引入maven依赖
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>5.12.0</version>
</dependency>
生产者代码
package com.epoint.demo.rabbitmq;
import com.epoint.demo.Constants;
import com.rabbitmq.client.AMQP;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
/**
* Description:
*
* @author james
* @date 2021/6/22 17:13
*/
public class Producer
{
public static void main(String[] args) throws Exception {
long start = 0L;
long end = 0L;
try {
/**
* 创建连接连接到MabbitMQ
*/
ConnectionFactory factory = new ConnectionFactory();
factory.setHost(Constants.RABBITMQ_SERVER);
factory.setUsername(Constants.RABBITMQ_USERNAME);
factory.setPassword(Constants.RABBITMQ_PASSWORD);
factory.setPort(AMQP.PROTOCOL.PORT);
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
// 指定一个队列
channel.queueDeclare(Constants.QUEUE, false, false, false, null);
start = System.currentTimeMillis();
for (int i = 0; i < Constants.COUNT_3000000; i++) {
String msg = Constants.MESSAGE_1 + i;
channel.basicPublish("", Constants.QUEUE, null, msg.getBytes());
System.out.println("publish " + msg);
}
// 关闭频道和连接
end = System.currentTimeMillis();
channel.close();
connection.close();
}
finally {
System.out.println((end - start) + "ms");
}
}
}
消费者代码
package com.epoint.demo.rabbitmq;
import com.epoint.demo.Constants;
import com.rabbitmq.client.*;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
/**
* Description:
*
* @author james
* @date 2021/6/22 17:20
*/
public class Consumer
{
public static void main(String[] args) throws IOException, TimeoutException {
// 创建连接工厂
ConnectionFactory factory = new ConnectionFactory();
factory.setHost(Constants.RABBITMQ_SERVER);
factory.setUsername(Constants.RABBITMQ_USERNAME);
factory.setPassword(Constants.RABBITMQ_PASSWORD);
factory.setPort(AMQP.PROTOCOL.PORT);
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
// 声明要关注的队列
channel.queueDeclare(Constants.QUEUE, false, false, false, null);
System.out.println("Customer Waiting Received messages");
// 告诉服务器我们需要那个频道的消息,如果频道中有消息,就会执行回调函数handleDelivery
DefaultConsumer consumer = new DefaultConsumer(channel)
{
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties,
byte[] body) throws IOException {
String message = new String(body, "UTF-8");
System.out.println("Customer Received '" + message + "'");
}
};
// 自动回复队列应答 -- RabbitMQ中的消息确认机制
channel.basicConsume(Constants.QUEUE, true, consumer);
}
}
30W个消息,每个消息为"helloworld!-----i"
kafka生产者(5次连续测试)耗时1791ms/1631ms/1575ms/1664ms/1672ms 平均耗时16s左右
kafka生产者(3次连续测试)耗时(同时消费)1853ms/1801ms/1892ms 平均耗时18s左右
rabbitmq生产者(5次连续测试)耗时25407ms/25776ms/27000ms/23758ms/25834ms平均耗时25s左右
rabbitmq生产者(3次连续测试)耗时(同时消费)16930ms/16652ms/16252ms 平均耗时16s左右
消费堆积情况下,kafka明显比rabbitmq发布消息速度快很多
非消费堆积的情况下,kafka和rabbitmq发布消息速度差不多
300W个消息,每个消息为"helloworld!-----i"
kafka生产者耗时12537ms,消费者耗时46s左右
kafka生产者耗时(同时消费)17205ms
rabbitmq生产者耗时350775ms,消费者耗时203s左右
rabbitmq生产者耗时(同时消费)233558ms
不管是否消费堆积的情况下,kafka都比rabbitmq发布消息速度快很多
根据以上测试可得出
-
消费堆积:不管消息量的多少,kafka都比rabbitmq发布消息快很多
-
非消费堆积:消息量越大,rabbitmq发布消息速度会慢得多,kafka也会成比例变慢
消息量10倍增加,rabbitmq发布耗时增加15倍左右,kafka发布耗时增加8倍左右
结论
由于javademo与压测工具测试环境有差异,javademo依赖于客户端工具代码、主机与虚拟机网络开销,所以两种测试方式无法直接对比
javademo测试得出:
kafka消息发布速度比rabbitmq快很多,尤其在消费堆积的情况下
压测工具测试得出:
kafka最大消息写入数可达到238027记录/s,95%消息延时2440ms
rabbitmq最大消息写入数29000记录/s,95%消息延时5970ms
综上所述,同等环境下,kafka每秒写入数比rabbitmq大,消息吞吐量比rabbitmq大,以上在单机环境下测试,所以单台服务器的测试结果,对评估集群服务是否满足上线后实际应用的需求,很有参考价值。
五、集成
集群部署
以上测试在单机环境下进行,实际生产环境肯定是集群模式,所以以下介绍以集群为例
三台本地服务器(1C+2G)
Kafka
基础环境jdk1.8,kafka包下载地址www.apache.org/dyn/closer.…
我在本地安装了vm虚拟机,克隆了三台服务器,地址分别为192.168.244.130、192.168.244.131、192.168.244.132
-
Zookeeper集群
修改机器192.168.244.130
-
Kafka安装包中已经集成了Zookeeper,只需要将kafka安装包上传至/opt目录
-
解压
tar -zxvf kafka_2.12-2.8.0.tgz -
进入kafka config目录
cd /opt/kafka_2.12-2.8.0/config -
修改zookeeper.peoperties
vi zookeeper.properties,按照下图修改相应配置- data.Dir 为zookeeper的数据目录
- 2888端口号是zookeeper服务之间通信的端口,3888端口是zookeeper与其他应用程序通信的端口。
- 创建myid文件,进入/data/zookeeper目录(dataDir目录),
echo 0 > myid,写入“0”(这个0与上一步zookeeper.properties中server.0后缀对应,保证三台机器不同)
至此192.168.244.130机器zookeeper配置完成,同理,配置另外两台机器
启动zookeeper集群,在三台机器上
cd /opt/kafka_2.12-2.8.0/bin,分别执行以下命令nohup ./zookeeper-server-start.sh ../config/zookeeper.properties &>> /data/zookeeper/zookeeper.log &三台机器未全部启动时,日志会出现找不到其他节点的错误,暂时先不管
等三台机器全都启动完成,日志中没报错说明集群启动成功了
-
-
Kafka集群
-
进入kafka config目录
cd /opt/kafka_2.12-2.8.0/config -
修改server.properties
vi server.properties- broker.id:节点编号
- advertised.listeners:监听本机地址
- log.dirs:日志目录
- num.partitions:分区数量(可自由配置)
- zookeeper.connect:zookeeper地址
-
至此192.168.244.130机器kafka配置完成,同理,配置另外两台机器
启动kafka集群,在三台机器上`cd /opt/kafka_2.12-2.8.0/bin`,分别执行以下命令
`nohup ./kafka-server-start.sh ../config/server.properties &>> /data/kafka-logs/kafka.log &`
**等三台机器全都启动完成,日志中没报错说明集群启动成功了**
3. 测试集群
以下操作可以在任意一个节点完成
-
创建topic(三分区,两副本)
./kafka-topics.sh -create --zookeeper 192.168.244.130:2181,192.168.244.131:2181,192.168.244.132:2181 -replication-factor 2 --partitions 3 --topic cluster-test3 -
列出已创建topic
./kafka-topics.sh --list --zookeeper 192.168.244.130:2181 -
模拟客户端发送消息
./kafka-console-producer.sh --broker-list 192.168.244.130:9092 --topic cluster-test3 -
模拟客户端接收消息
./kafka-console-consumer.sh --bootstrap-server 192.168.244.130:9092 --topic cluster-test3 --from-beginning
RabbitMQ
安装步骤可参考juejin.cn/post/693087…
分别在三台机器上都按照以上网址步骤安装好单机RabbitMQ,然后通过rabbitmqctl搭建集群环境
修改机器192.168.244.130
-
修改hostname,
hostnamectl set-hostname node1 -
修改hosts,
vi /etc/hosts,加入下列三行代码(修改完之后需要重新打开终端才生效)
3. 按照上述步骤同样的修改机器192.168.244.131和192.168.244.132
-
分别启动三台机器上的RabbitMQ,
service rabbitmq-server start -
进入node2(192.168.244.131),按以下指令操作
rabbitmqctl stop_apprabbitmqctl resetrabbitmqctl join_cluster rabbit@node1rabbitmqctl start_app如一切正常,则会出现如下图所示
6. 进入node3(192.168.244.132),重复第5步操作
- 至此,集群搭建完成,可登录http://192.168.244.130:15672/查看界面,出现以下界面表示集群搭建成功
现在搭建的集群是默认的普通集群,普通集群中节点可以共享集群中的exchange,routingKey和queue,但是queue中的消息只保存在首次声明queue的节点中。任意节点的消费者都可以消费其他节点的消息,比如消费者连接node1节点的消费者(代码中建立Connection时,使用的node1的IP)可以消费节点node2的队列queue2中的消息,消息传输过程是:node2把queue2中的消息传输给node1,然后node1节点把消息发送给consumer。因为queue1中的消息只保存在首次声明queue1的节点中,这样就有一个问题:如果某一个node节点挂掉了,那么只能等待该节点重新连接才能继续处理该节点内的消息(如果没有设置持久化的话,节点挂掉后消息会直接丢失)。如下图,node3节点挂掉后,queue3队列就down掉了,不能被访问。
针对上边的问题,我们可能会想到:如果可以让rabbitmq中的节点像redis集群的节点一样,每一个节点都保存所有的消息,比如让node1不仅仅保存自己队列queue1的消息,还保存其他节点的队列queue2和queue3中的消息,node2和node3节点也一样,这样就不用担心宕机的问题了。rabbitmq也提供了这样的功能:镜像队列。镜像队列由一个master和多个slave组成,使用镜像队列消息会自动在镜像节点间同步,而不是在consumer取数据时临时拉取。
rabbitmqctl set_policy ha-all "^queue" '{"ha-mode":"all","ha-sync-mode":"automatic"}'# ha-all:为策略名称;# ^queue:为匹配符,只有一个^代表匹配所有,^abc为匹配名称以abc开头的queue或exchange;# ha-mode:为同步模式,一共3种模式:# ①all-所有(所有的节点都同步消息),# ②exctly-指定节点的数目(需配置ha-params参数,此参数为int类型比如2,在集群中随机抽取2个节点同步消息)# ③nodes-指定具体节点(需配置ha-params参数,此参数为数组类型比如["rabbit@node1","rabbit@node2"],明确指定在这两个节点上同步消息)。
node3节点挂了之后,queue3的node就变成了node1,如下图所示
我们发现node3节点挂了后,node1自动成为了queue3的node,queue3不会down掉,可以正常的添加/删除/获取消息,这就解决了普通集群宕机的问题。使用镜像队列,因为各个节点要同步消息,所以比较耗费资源,一般在可靠性比较高的场景使用镜像队列。
API集成(springboot)
pom.xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
kafka
yml配置
kafka:
# kafka集群服务器地址
bootstrap-servers: 192.168.244.130:9092,192.168.244.131:9092,192.168.244.132:9092
producer:
# 发生错误后,消息重发的次数。
retries: 0
#当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。
batch-size: 16384
# 设置生产者内存缓冲区的大小。
buffer-memory: 33554432
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。
# acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。
# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
acks: 1
consumer:
# 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D
auto-commit-interval: 1S
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)
# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录
auto-offset-reset: earliest
# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量
enable-auto-commit: false
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 在侦听器容器中运行的线程数。
concurrency: 5
#listner负责ack,每调用一次,就立即commit
ack-mode: manual_immediate
missing-topics-fatal: false
生产者
package com.epoint.test.kafka;
import lombok.extern.slf4j.Slf4j;
import org.jetbrains.annotations.NotNull;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
/**
* Description:
*
* @author james
* @date 2021/7/13 11:00
*/
@Slf4j
@Component
public class KafkaProducer
{
public static final String TOPIC_TEST1 = "topic_test1";
public static final String GROUP_TEST1 = "group_test1";
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
public String sendMsg1(String message) {
//发送消息
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(TOPIC_TEST1, message);
future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>()
{
@Override
public void onFailure(@NotNull Throwable throwable) {
//发送失败的处理
log.info(TOPIC_TEST1 + " - 生产者 发送消息失败:" + throwable.getMessage());
}
@Override
public void onSuccess(SendResult<String, Object> stringObjectSendResult) {
//成功的处理
log.info(TOPIC_TEST1 + " - 生产者 发送消息成功:" + stringObjectSendResult.toString());
}
});
return "success";
}
}
消费者(yml中配置了需要手动确认,所以这边需要ack.acknowledge()手动确认,也可以配置自动确认,那这边就不需要ack.acknowledge())
package com.epoint.test.kafka;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Component;
import java.util.Optional;
/**
* Description:
*
* @author james
* @date 2021/7/13 11:02
*/
@Slf4j
@Component
public class KafkaConsumer
{
@KafkaListener(topics = KafkaProducer.TOPIC_TEST1, groupId = KafkaProducer.GROUP_TEST1)
public void listener1(ConsumerRecord<?, ?> record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {
Optional message = Optional.ofNullable(record.value());
if (message.isPresent()) {
Object msg = message.get();
log.info("listener1 消费了: Topic:{}, Message:{}, offset:{}, partition:{}", topic, msg, record.offset(), record.partition());
//手动提交
ack.acknowledge();
}
}
}
测试类
@Autowired
private KafkaProducer kafkaProducer;
@GetMapping("/kafka/{message}")
public String kafka(@PathVariable("message") String message) {
log.info("kafka ===> message:{}", message);
return kafkaProducer.sendMsg1(message);
}
启动springboot,默认端口8080,通过访问http://localhost:8080/kafka/message1111111111,即可发送消息,通过后台日志可观察消费详情
RabbitMQ
yml配置
rabbitmq:
addresses: 192.168.244.130:5672,192.168.244.131:5672,192.168.244.132:6572
username: epoint
password: epoint
#手动确认
#确认消息已发送到交换机
#publisher-confirm-type: correlated
#确认消息已发送到队列
#publisher-returns: false
-
Direct交换机配置
package com.epoint.test.rabbitmq.config; import org.springframework.amqp.core.Binding; import org.springframework.amqp.core.BindingBuilder; import org.springframework.amqp.core.DirectExchange; import org.springframework.amqp.core.Queue; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; /** * Description: 直连型交换机,根据消息携带的路由键,将消息转发给对应的队列 * * @author james * @date 2021/7/13 14:20 */ @Configuration public class DirectRabbitMQConfig { public static final String QUEUE = "directQueue"; public static final String EXCHANGE = "directExchange"; public static final String ROUTING = "direct.routing"; /** * 交换机 */ @Bean public DirectExchange myDirectExchange() { // 参数意义: // name: 名称 // durable: true // autoDelete: 自动删除 return new DirectExchange(EXCHANGE, true, false); } /** * 队列 */ @Bean public Queue myDirectQueue() { return new Queue(QUEUE, true); } /** * 绑定 */ @Bean public Binding bindingDirect() { return BindingBuilder .bind(myDirectQueue()) .to(myDirectExchange()) .with(ROUTING); } } -
Fanout交换机配置
package com.epoint.test.rabbitmq.config; import org.springframework.amqp.core.Binding; import org.springframework.amqp.core.BindingBuilder; import org.springframework.amqp.core.FanoutExchange; import org.springframework.amqp.core.Queue; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; /** * Description: 扇形交换机,接收到消息后会将消息转发到所有队列,类似发布/广播模式 * * @author james * @date 2021/7/13 14:26 */ @Configuration public class FanoutRabbitMQConfig { public static final String QUEUE_A = "fanoutQueueA"; public static final String QUEUE_B = "fanoutQueueB"; public static final String QUEUE_C = "fanoutQueueC"; public static final String EXCHANGE = "fanoutExchange"; // ----- 交换机 ----- @Bean public FanoutExchange fanoutExchange() { return new FanoutExchange(EXCHANGE, true, false); } // ----- 队列 ----- @Bean public Queue fanoutQueueA() { return new Queue(QUEUE_A, true); } @Bean public Queue fanoutQueueB() { return new Queue(QUEUE_B, true); } @Bean public Queue fanoutQueueC() { return new Queue(QUEUE_C, true); } // ----- 绑定 ----- @Bean public Binding bindingFanoutA() { return BindingBuilder.bind(fanoutQueueA()).to(fanoutExchange()); } @Bean public Binding bindingFanoutB() { return BindingBuilder.bind(fanoutQueueB()).to(fanoutExchange()); } @Bean public Binding bindingFanoutC() { return BindingBuilder.bind(fanoutQueueC()).to(fanoutExchange()); } } -
Topic交换机配置
package com.epoint.test.rabbitmq.config; import org.springframework.amqp.core.Binding; import org.springframework.amqp.core.BindingBuilder; import org.springframework.amqp.core.Queue; import org.springframework.amqp.core.TopicExchange; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; /** * Description: 支持binding key和routing key的模糊匹配,会把消息路由到满足条件的Queue * * @author james * @date 2021/7/13 14:33 */ @Configuration public class TopicRabbitMQConfig { public static final String QUEUE_1 = "topicQueue1"; public static final String QUEUE_2 = "topicQueue2"; public static final String EXCHANGE = "topicExchange"; public static final String ROUTING_01 = "topic.01"; public static final String ROUTING_ALL = "topic.#"; // 交换机 @Bean public TopicExchange myTopicExchange() { return new TopicExchange(EXCHANGE, true, false); } // ----- 队列 ----- @Bean public Queue myTopicQueue1() { return new Queue(QUEUE_1, true); } @Bean Queue myTopicQueue2() { return new Queue(QUEUE_2, true); } /** * 绑定路由键为topic.01 */ @Bean public Binding binding1() { return BindingBuilder.bind(myTopicQueue1()).to(myTopicExchange()).with(ROUTING_01); } /** * 绑定路由键为topic.#规则 */ @Bean public Binding binding2() { return BindingBuilder.bind(myTopicQueue2()).to(myTopicExchange()).with(ROUTING_ALL); } }
生产者
package com.epoint.test.rabbitmq;
import com.epoint.test.rabbitmq.config.AckRabbitMQConfig;
import com.epoint.test.rabbitmq.config.DirectRabbitMQConfig;
import com.epoint.test.rabbitmq.config.FanoutRabbitMQConfig;
import com.epoint.test.rabbitmq.config.TopicRabbitMQConfig;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
/**
* Description:
*
* @author james
* @date 2021/7/13 13:44
*/
@Slf4j
@Component
public class RabbitMQProducer
{
@Autowired
private RabbitTemplate rabbitTemplate;
public void sendDirect(String message) {
rabbitTemplate.convertAndSend(DirectRabbitMQConfig.EXCHANGE, DirectRabbitMQConfig.ROUTING, message);
log.info("sendDirect 生产者 queue:{} 发送消息成功:{}", DirectRabbitMQConfig.QUEUE, message);
}
public void sendFanout(String message) {
rabbitTemplate.convertAndSend(FanoutRabbitMQConfig.EXCHANGE, null, message);
log.info("sendFanout 生产者 queue:{},{},{} 发送消息成功:{}", FanoutRabbitMQConfig.QUEUE_A, FanoutRabbitMQConfig.QUEUE_B, FanoutRabbitMQConfig.QUEUE_C, message);
}
public void sendTopic(String message) {
String message1 = message + " topic.01";
rabbitTemplate.convertAndSend(TopicRabbitMQConfig.EXCHANGE, TopicRabbitMQConfig.ROUTING_01, message1);
log.info("sendTopic 生产者 queue:{} 发送消息成功:{}", TopicRabbitMQConfig.QUEUE_1, message1);
String message2 = message + " topic.xxx";
rabbitTemplate.convertAndSend(TopicRabbitMQConfig.EXCHANGE, TopicRabbitMQConfig.ROUTING_ALL, message2);
log.info("sendTopic 生产者 queue:{} 发送消息成功:{}", TopicRabbitMQConfig.QUEUE_2, message2);
}
public void sendDirectAck(String message) {
rabbitTemplate.convertAndSend(AckRabbitMQConfig.EXCHANGE, AckRabbitMQConfig.ROUTING, message);
log.info("sendDirectAck 生产者 queue:{} 发送消息成功:{}", AckRabbitMQConfig.QUEUE, message);
}
}
消费者
package com.epoint.test.rabbitmq;
import com.epoint.test.rabbitmq.config.DirectRabbitMQConfig;
import com.epoint.test.rabbitmq.config.FanoutRabbitMQConfig;
import com.epoint.test.rabbitmq.config.TopicRabbitMQConfig;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.rabbit.annotation.RabbitHandler;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
/**
* Description:
*
* @author james
* @date 2021/7/13 13:58
*/
@Slf4j
@Component
public class RabbitMQConsumer
{
//Direct
@RabbitHandler
@RabbitListener(queues = DirectRabbitMQConfig.QUEUE)
public void directListener(String message) {
log.info("directListener:{}", message);
}
//Fanout
@RabbitHandler
@RabbitListener(queues = FanoutRabbitMQConfig.QUEUE_A)
public void fanoutListenerA(String message) {
log.info("fanoutListenerA:{}", message);
}
@RabbitHandler
@RabbitListener(queues = FanoutRabbitMQConfig.QUEUE_B)
public void fanoutListenerB(String message) {
log.info("fanoutListenerB:{}", message);
}
@RabbitHandler
@RabbitListener(queues = FanoutRabbitMQConfig.QUEUE_C)
public void fanoutListenerC(String message) {
log.info("fanoutListenerC:{}", message);
}
//Topic
@RabbitHandler
@RabbitListener(queues = TopicRabbitMQConfig.QUEUE_1)
public void topicListener1(String message) {
log.info("topicListener1:{}", message);
}
@RabbitHandler
@RabbitListener(queues = TopicRabbitMQConfig.QUEUE_2)
public void topicListener2(String message) {
log.info("topicListener2:{}", message);
}
}
分别对三种交换机的情况测试,通过以下方法
@Autowired
private RabbitMQProducer rabbitMQProducer;
@GetMapping("/rabbit/direct/{message}")
public String rabbitDirect(@PathVariable("message") String message) {
log.info("rabbit.direct ===> message:{}", message);
rabbitMQProducer.sendDirect(message);
return "success";
}
@GetMapping("/rabbit/fanout/{message}")
public String rabbitFanout(@PathVariable("message") String message) {
log.info("rabbit.fanout ===> message:{}", message);
rabbitMQProducer.sendFanout(message);
return "success";
}
@GetMapping("/rabbit/topic/{message}")
public String rabbitTopic(@PathVariable("message") String message) {
log.info("rabbit.topic ===> message:{}", message);
rabbitMQProducer.sendTopic(message);
return "success";
}
启动springboot,默认端口8080,通过访问http://localhost:8080/rabbit/direct/msgDirect,http://localhost:8080/rabbit/fanout/msgFanout,http://localhost:8080/rabbit/topic/msgTopic,即可发送消息,通过后台日志可观察消费详情
以上为自动确认,将yml中如下配置注释放开,即可进行手动确认配置
配置类
package com.epoint.test.rabbitmq.config;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.DirectExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.rabbit.connection.ConnectionFactory;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* Description: 手动确认配合直连型交换机
*
* @author james
* @date 2021/7/13 14:47
*/
@Slf4j
@Configuration
public class AckRabbitMQConfig
{
public static final String QUEUE = "ackQueue";
public static final String EXCHANGE = "ackExchange";
public static final String ROUTING = "ack.routing";
/**
* 交换机
*/
@Bean
public DirectExchange myDirectAckExchange() {
// 参数意义:
// name: 名称
// durable: true
// autoDelete: 自动删除
return new DirectExchange(EXCHANGE, true, false);
}
/**
* 队列
*/
@Bean
public Queue myDirectAckQueue() {
return new Queue(QUEUE, true);
}
/**
* 绑定
*/
@Bean
public Binding bindingDirectAck() {
return BindingBuilder
.bind(myDirectAckQueue())
.to(myDirectAckExchange())
.with(ROUTING);
}
@Bean
public RabbitTemplate createRabbitTemplate(ConnectionFactory connectionFactory) {
RabbitTemplate rabbitTemplate = new RabbitTemplate();
rabbitTemplate.setConnectionFactory(connectionFactory);
// 开启Mandatory, 才能触发回调函数,无论消息推送结果如何都强制调用回调函数
rabbitTemplate.setMandatory(true);
rabbitTemplate.setConfirmCallback((correlationData, ack, cause) -> {
log.info("ConfirmCallback: 相关数据:{}", correlationData);
log.info("ConfirmCallback: 确认情况:{}", ack);
log.info("ConfirmCallback: 原因:{}", cause);
});
rabbitTemplate.setReturnCallback((message, replyCode, replyText, exchange, routingKey) -> {
log.info("ReturnCallback: 消息:{}", message.toString());
log.info("ReturnCallback: 回应码:{}", replyCode);
log.info("ReturnCallback: 回应信息:{}", replyText);
log.info("ReturnCallback: 交换机:{}", exchange);
log.info("ReturnCallback: 路由键:{}", routingKey);
});
return rabbitTemplate;
}
}
监听配置
package com.epoint.test.rabbitmq.config;
import com.epoint.test.rabbitmq.AckConsumer;
import org.springframework.amqp.core.AcknowledgeMode;
import org.springframework.amqp.rabbit.connection.CachingConnectionFactory;
import org.springframework.amqp.rabbit.listener.SimpleMessageListenerContainer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* Description:
*
* @author james
* @date 2021/7/13 14:50
*/
@Configuration
public class MessageListenerConfig
{
@Autowired
private CachingConnectionFactory cachingConnectionFactory;
@Autowired
private AckConsumer ackConsumer;
@Bean
public SimpleMessageListenerContainer simpleMessageListenerContainer() {
SimpleMessageListenerContainer container = new SimpleMessageListenerContainer(cachingConnectionFactory);
// 监听队列名
container.setQueueNames(AckRabbitMQConfig.QUEUE);
// 当前消费者数量
container.setConcurrentConsumers(1);
// 最大消费者数量
container.setMaxConcurrentConsumers(1);
// 手动确认
container.setAcknowledgeMode(AcknowledgeMode.MANUAL);
// 设置监听器
container.setMessageListener(ackConsumer);
return container;
}
}
消费者
package com.epoint.test.rabbitmq;
import com.rabbitmq.client.Channel;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.listener.api.ChannelAwareMessageListener;
import org.springframework.stereotype.Component;
/**
* Description:
*
* @author james
* @date 2021/7/13 14:50
*/
@Slf4j
@Component
public class AckConsumer implements ChannelAwareMessageListener
{
@Override
public void onMessage(Message message, Channel channel) throws Exception {
// 消息的唯一性ID
long deliveryTag = message.getMessageProperties().getDeliveryTag();
try {
String msg = message.toString();
log.info("消息: " + msg);
log.info("消息来自: " + message.getMessageProperties().getConsumerQueue());
// 手动确认
channel.basicAck(deliveryTag, true);
}
catch (Exception e) {
// 拒绝策略
channel.basicReject(deliveryTag, false);
e.printStackTrace();
}
}
}
测试方法
@GetMapping("/rabbit/directack/{message}")
public String rabbitDirectAck(@PathVariable("message") String message) {
log.info("rabbit.directack ===> message:{}", message);
rabbitMQProducer.sendDirectAck(message);
return "success";
}
启动springboot,默认端口8080,通过访问http://localhost:8080/rabbit/directack/msgDirectAck,即可发送消息,通过后台日志可观察消费详情
FAQ
如何保证高可用
rabbitmq
rabbitmq有三种模式:单机、普通集群、镜像集群
-
单机:用作demo测试,生产一般不会使用
-
普通集群:多台机器启动多个实例,但是创建的queue,只会存在于一个rabbitmq实例上;
流程:系统A写数据到queue中(queue存在于实例1),系统B需要消费queue中的数据(随机连接实例),
但是queue在实例1中,而系统B连接的是实例3,所以需要拉取实例1中的queue的数据,这就导致了数据拉取的开销,其实这就是普通的数据集群,没有做到分布式
-
镜像集群:创建的queue,无论是原数据还是queue里的消息,都会存在与多个实例,每次写消息的时候,都会自动把消息同步到多个实例的queue中
缺陷:需要同步到所有机器,同步过程性能开销太大;扩展性较差;
kafka
天然的分布式消息队列:多个broker组成,每个broker都是一个节点;创建一个topic,每个topic划分为多个partition;每个partition存在于不同的broker上,每个partition存放一部分数据;
kafka0.8之后提供了HA机制,就是replica副本机制。每个partition的数据都会同步到其他机器上,形成自己的多个replica副本,每个replica会选举出一个leader,生产和消费都会与这个leader交互,其他的replica就是follower。写数据的时候leader负责同步数据到follower,读的时候直接读leader。
如果某个broker挂了,那个broker上的partition在其他机器上都会有replica,如果挂的正好是leader,那就会重新选举一个leader,这样就形成了高可用;
关于数据持久化,生产者写leader,leader会将数据持久化到磁盘,接着其他follower会主动pullleader的数据,一旦follower同步好了,就会有ack发给leader,leader在收到ack之后,回写成功给生产者。
如何解决重复消费
无论消息队列是否可靠,都应该在程序内部做幂等性处理
kafka有offset概念,每次写消息,都会有一个唯一的offset,consumer消费之后,会把offset提交上去,代表我已经消费了,下次消费就从下一个offset来消费;
但如果consumer消费之后,offset还未提交,系统重启了或直接kill了,下次消费的话就会有重复消费,重复消费之后,系统应当做幂等性处理,可直接通过数据库主键,或者通过写redis,具体逻辑可根据具体业务来设计。
文章参考:
