C# 集合之Dictionary详解
开讲。
我们知道Dictionary的最大特点就是可以通过任意类型的key寻找值。而且是通过索引,速度极快。
该特点主要意义:数组能通过索引快速寻址,其他的集合基本都是以此为基础进行扩展而已。 但其索引值只能是int,某些情境下就显出Dictionary的便利性了。
那么问题就来了--C#是怎么做的呢,能使其做到泛型索引。
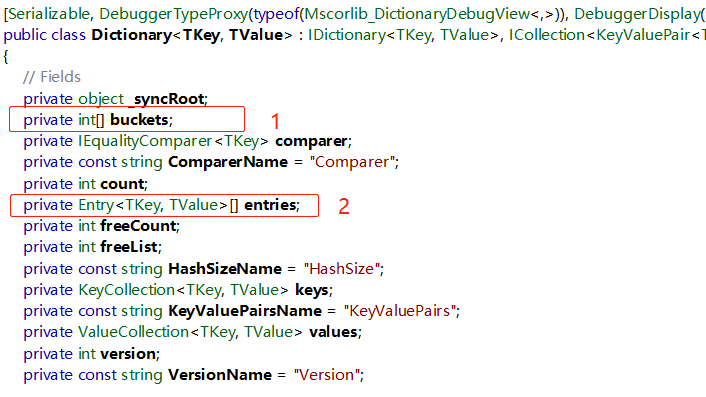
我们关注圈中的内容,这是Dictionary的本质 --- 两个数组,。这是典型的用空间换取时间的做法。
先来说下两数组分别代表什么。
1- buckets,int[] ,水桶!不过我觉得用仓库更为形象。eg: buckets = new int[3]; 表示三个仓库,i = buckets [0] ,if i = -1 表示该仓库为空,否则表示第一个仓库存储着东西。这个东西表示数组entries的索引。
2- entries , Entry<TKey,TValue>[] ,Entry是个结构,key,value就是我们的键值真实值,hashCode是key的哈希值,next可以理解为指针,这里先不具体展开。
[StructLayout(LayoutKind.Sequential)]
private struct Entry
{
public int hashCode;
public int next;
public TKey key;
public TValue value;
}
先说一下索引,如何用人话来解释呢?这么说吧,本身操作系统只支持地址寻址,如数组声明时会先存一个header,同时获取一个base地址指向这个header,其后的元素都是通过*(base+index)来进行寻址。
基于这个共识,Dictionary用泛型key索引的实现就得想方设法把key转换到上面数组索引上去。
也就是说要在记录的存储位置和它的关键字之间建立一个确定的对应关系 f,使每个关键字和结构中一个惟一的存储位置相对应。
因而在查找时,只要根据这个对应关系 f 找到给定值 K 的函数值 f(K)。若结构中存在关键字和 K 相等的记录。在此,我们称这个对应关系 f 为哈希 (Hash) 函数,按这个思想建立的表为哈希表。
回到Dictionary,这个f(K)就存在于key跟buckets之间:
dic[key]加值的实现:entries数组加1,获取i-->key-->获取hashCode-->f(hashCode)-->确定key对应buckets中的某个仓库(buckets对应的索引)-->设置仓库里的东西(entries的索引 = i)
dic[key]取值的实现:key-->获取hashCode-->f(hashCode)-->确定key对应buckets中的某个仓库(buckets对应的索引)--> 获取仓库里的东西(entries的索引i,上面有说到)-->真实的值entries[i]
上面的流程中只有一个(f(K)获取仓库索引)让我们很难受,因为不认识,那现在问题变成了这个f(K)如何实现了。
实现:
` int index = hashCode % buckets.Length;
这叫做除留余数法,哈希函数的其中一种实现。如果你自己写一个MyDictionary,可以用其他的哈希函数。
举个例子,假设两数组初始大小为3, this.comparer.GetHashCode(4) & 0x7fffffff = 4:
Dictionary<int, string> dic = new Dictionary<int, string>();
dic.Add(4, "value");
i=0,key=4--> hashCode=4.GetHashCode()=4--> f(hashCode)=4 % 3 = 1-->第1号仓库-->东西 i = 0.
此时两数组状态为:
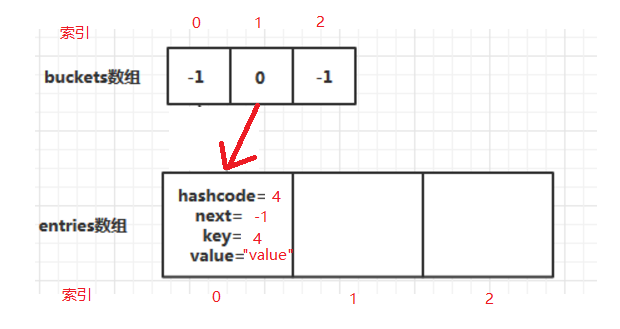
取值按照之前说的顺序进行,仿佛已经完美。但这里还有个问题,不同的key生成的hashCode经过f(K)生成的值不是唯一的。即一个仓库可能会放很多东西。
C#是这么解决的,每次往仓库放东西的时候,先判断有没有东西(buckets[index] 是否为 -1),如果有,则进行修改。
如再:
dic.Add(7, "value");
dic.Add(10, "value");
f(entries[1]. hashCode)=7 % 3 = 1也在第一号仓库,则修改buckets[1] = 1。
同时修改entries[1].next = 0;//上一个仓库的东西
f(entries[2].hashCode)=10 % 3 = 1也在第一号仓库,则再修改buckets[1] = 2。
同时修改entries[1].next = 1;//上一个仓库的东西
这样相当于1号仓库存了一个单向链表,entries:2-1-0。
成功解决。
这里有人如果看过这些集合源码的话知道数组一般会有一个默认大小(当然我们初始化集合的时候也可以手动传入capacity),总之,Length不可能无限大。
那么当集合满的时候,我们需对集合进行扩容,C#一般直接Length*2。那么buckets.Length就是可变的,上面的f(K)结果也就不是恒定的。
C#对此的解决放在了扩容这一步:
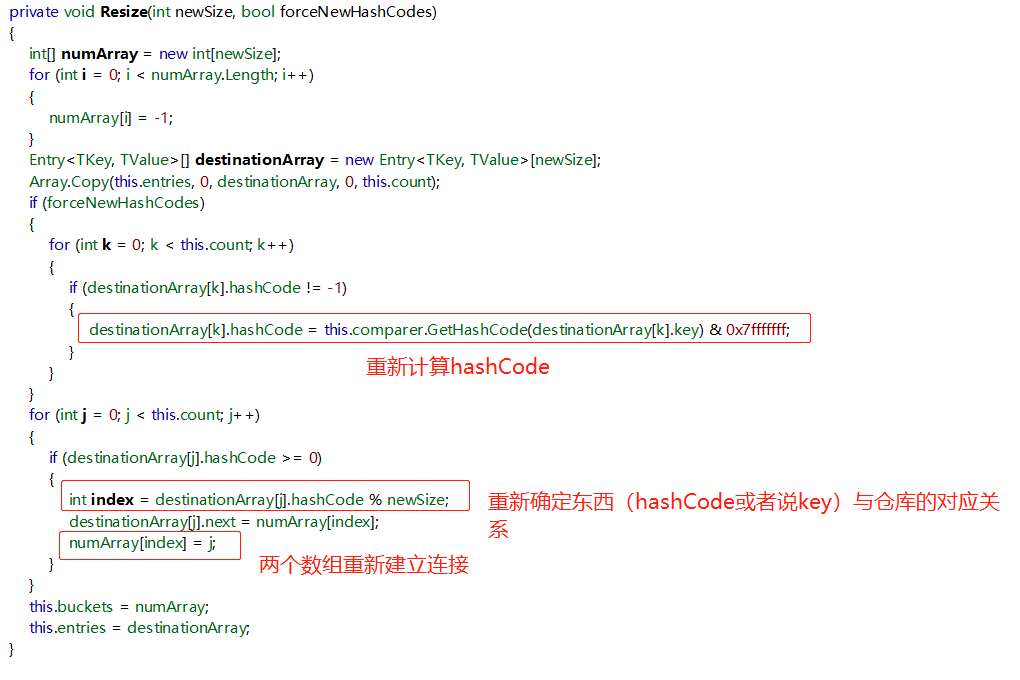
可以看到扩容实质就是新开辟一个更大空间的数组,讲道理是耗资源的。所以我们在初始化集合的时候,每次都给定一个合适的Capacity,讲道理是一个老油条该干的事儿。
上面说的这就是所谓“用空间换取时间的做法”,两个数组存了一个集合,而集合中我们最关心的value仿佛是个主角,一堆配角作陪。
现在看下源码实现:
索引器取值:
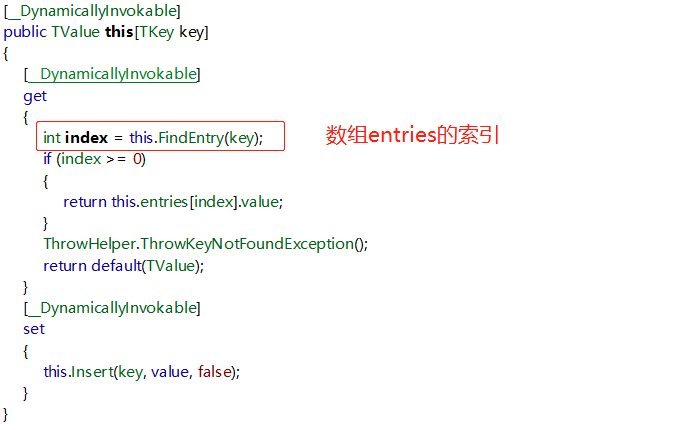
具体实现:

1,2,3,4,5就是本文的重点。基本都讲到了,其中4 ,5 -- (this.entries[i].hashCode == num) && this.comparer.Equals(this.entries[i].key, key):确定唯一key value对的条件,hashCode相等,key也得相等。
说明hashCode也有相等的情况,其实这里 (this.entries[i].hashCode == num)这个条件可以省略,因为如果key Equal则hashCode 肯定相等。当然&&符号会先计算第一个条件,比较hashCode快得多,先过滤掉一大部分元素,最后再用Equals比较确定。
也就是
hash code 是整数,相等判断的性能高。
hash code 相等才做较慢的键相等判断。
这是一种性能优化。
Thanks All.
欢迎讨论~
感谢阅读~
个人公众号:


