HtmlAgilityPack是C#解析HTML的神器,相信用过HtmlAgilityPack这个组件的人都不会否认这一点。虽然其官方文档很少,但只要GOOGLE,BAIDU一下,网上还是有很多关于介绍此神器的文章。具体的使用在这里就不多列举了,今天最主要介绍的是C#中,如果通过HtmlAgilityPack这个组件来获取有循环列表的数据节点信息的。当然,这里的循环可以是任意的HTML标签,比如ul中的li,或者有着相同class的div都行,下面来baidu搜索HtmlAgilityPack来做示例:
首先用Nuget管理工具Package Manager Console将组件添加到需要的项目:
 以下是整个示例的实现源代码:
以下是整个示例的实现源代码:
Install-Package HtmlAgilityPack然后在需要使用HtmlAgilityPack组件的cs文件中引入其命名空间:
using HtmlAgilityPack;完成以上两步之后,我们便可下载网页源码并作解析工作了,先看解析结果:
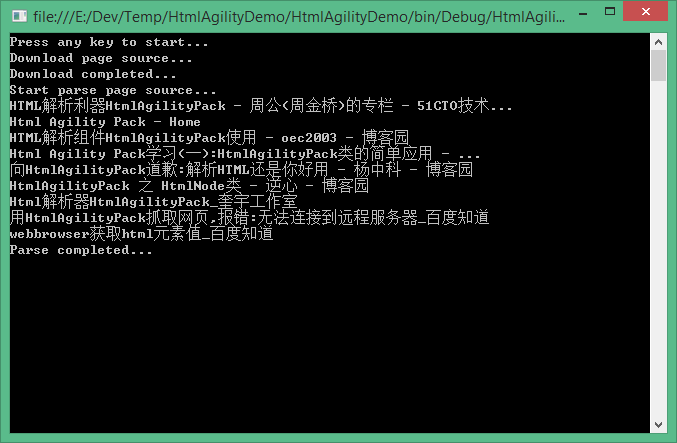 以下是整个示例的实现源代码:
以下是整个示例的实现源代码:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using HtmlAgilityPack;
using System.Net;
using System.IO;
namespace HtmlAgilityDemo
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("Press any key to start...");
Console.ReadKey();
LoopListParser();
Console.ReadKey();
}
static void LoopListParser()
{
Console.WriteLine("Download page source...");
var html = GetWebPageContentFromUrl("http://www.baidu.com/s?wd=htmlagilitypack&rsv_spt=1&issp=1&f=8&rsv_bp=0&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_sug3=15&rsv_sug4=944&rsv_sug1=14&rsv_sug2=0&inputT=7");
//Console.WriteLine(html);
Console.WriteLine("Download completed...");
Console.WriteLine("Start parse page source...");
Pareser(html);
Console.WriteLine("Parse completed...");
}
static void Pareser(string html)
{
var doc = new HtmlDocument();
doc.LoadHtml(html);
var nodes = doc.DocumentNode.SelectNodes("//div[@tpl='se_com_default']");
foreach (HtmlNode node in nodes)
{
//TODO:获取单个列表的标题
var title = node.SelectSingleNode(".//h3") != null ? node.SelectSingleNode(".//h3").InnerText : "";
Console.WriteLine(title);
}
}
static string DownloadPageSource(string url)
{
var html = "";
//直接使用WebClient下载网页,全出现乱码的情况
//var client = new WebClient();
//client.DownloadStringCompleted += (sender, e) =>
//{
// html=e.Result;
//};
//client.DownloadStringAsync(new Uri("http://www.baidu.com/s?wd=htmlagilitypack&rsv_spt=1&issp=1&f=8&rsv_bp=0&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_sug3=15&rsv_sug4=944&rsv_sug1=14&rsv_sug2=0&inputT=7"));
return html;
}
static string GetWebPageContentFromUrl(string url, int timeout = 30)
{
try
{
string pageContent;
var myRequest = (HttpWebRequest)WebRequest.Create(url);
myRequest.Method = "GET";
myRequest.Timeout = 1000 * timeout;
myRequest.AllowAutoRedirect = true;
var myResponse = (HttpWebResponse)myRequest.GetResponse();
using (var sr = new StreamReader(myResponse.GetResponseStream(), Encoding.GetEncoding((myResponse.CharacterSet))))
{
pageContent = sr.ReadToEnd();
myResponse.Close();
}
return pageContent;
}
catch (Exception ex)
{
throw new Exception(ex.Message);
}
}
}
}
本示例中用到了Xpath,如有不了解的同学,可以参考:http://www.w3school.com.cn/xpath/xpath_syntax.asp
版权声明:本作品系原创,版权归码友网所有,如未经许可,禁止任何形式转载,违者必究。

发表评论
登录用户才能发表评论, 请 登 录 或者 注册